
一、Hadoop
定义
狭义上:以Hadoop软件本身(hadoop.apache.org),指一个用于大数据分布式存储(HDFS),分布式计算(MapReduce)和资源调度(YARN)的平台,这三样只能用来做离线批处理,不能用于实时处理,因此才需要生态系统的其他的组件。
广义上:指的是hadoop的生态系统,即其他各种组件在内的一整套软件(sqoop,flume,spark,flink,hbase,kafka,cdh环境等)。hadoop生态系统是一个很庞大的概念,hadoop只是其中最重要最基础的部分,生态系统的每一个子系统只结局的某一个特定的问题域。不是一个全能系统,而是多个小而精的系统。
组成
Hadoop common:提供一些通用的功能支持其他hadoop模块。
Hadoop Distributed File System:即分布式文件系统,简称HDFS。主要用来做数据存储,并提供对应用数据高吞吐量的访问。
Hadoop MapReduce:基于yarn的,能用来并行处理大数据集的计算框架。
Hadoop Yarn:用于作业调度和集群资源管理的框架。
二、HDFS概述
定义
Hdfs(hadoop distribute file system),他是一个文件系统,用于存储文件,通过目录树来定位文件:其次,他是分布式的,有很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
Hdfs的使用场景,适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据存放。
优点
高容错性
数据自动保存多个副本。 (默认是三分)通过增加副本的形式,提高容错性
某一个副本丢失以后,它可以自动恢复
适合大数据处理
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
文件规模:能够处理百万规模以上的文件数量,
可构建在廉价机器上,通过多副本机制,提高可靠性
缺点
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的
- 无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标
- 不支持并发写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写(重点)
- 仅支持数据append(追加),不支持文件的随机修改
hdfs支持的三种模式
- Local (Standalone) Mode :本地模式,不启动进程,实际工作中从来没用过
- Pseudo-Distributed Mode:伪分布式,启动单个进程(1大 小),应用场景:学习
- Fully-Distributed Mode 集群模式,启动多个进程(2个大多个小),应用场景:生产(CDH,按量付费)
三、HDFS架构

1)NameNode(nn):Master,它是一个主管、管理者。
管理HDFS的名称空间
- 文件的名称、目录结构、权限、大小、所属用户用户组 时间
处理客户端读写请求
配置副本策略
管理数据块(Block)映射信息
文件被切割哪些块、块(块本身+2副本=3个块)分布在哪些DN节点上,blockmap 块映射。
不会持久化存储这种映射关系,是通过集群启动和运行时候,DN定期给NN汇报blockreport(BR),然后NN在内存中动态维护这种映射关系;
2)DataNode:Slave。NameNode下达命令,DataNode执行实际的操作
存储实际的数据块和块的校验和
执行数据块的读/写操作
定期给NN发送块报告
1
2dfs.blockreport.intervalMsec 21600000=6h
dfs.datanode.directoryscan.interval 21600s=6h
3)Client:客户端
- 文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或者写入数据
- Client提供一些命令来管理HDFS,比如NameNode格式化
- Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作
4)Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
edits 编辑日志文件
fsimage 镜像文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26NN:
-rw-rw-r-- 1 hadoop hadoop 42 Nov 28 08:07 edits_0000000000000000256-0000000000000000257
-rw-rw-r-- 1 hadoop hadoop 42 Nov 28 09:07 edits_0000000000000000258-0000000000000000259
-rw-rw-r-- 1 hadoop hadoop 1048576 Nov 28 09:07 edits_inprogress_0000000000000000260
-rw-rw-r-- 1 hadoop hadoop 2874 Nov 28 08:07 fsimage_0000000000000000257
-rw-rw-r-- 1 hadoop hadoop 62 Nov 28 08:07 fsimage_0000000000000000257.md5
-rw-rw-r-- 1 hadoop hadoop 2874 Nov 28 09:07 fsimage_0000000000000000259
-rw-rw-r-- 1 hadoop hadoop 62 Nov 28 09:07 fsimage_0000000000000000259.md5
-rw-rw-r-- 1 hadoop hadoop 4 Nov 28 09:07 seen_txid
-rw-rw-r-- 1 hadoop hadoop 219 Nov 26 22:01 VERSION
[hadoop@hadoop001 current]$ pwd
/home/hadoop/tmp/hadoop-hadoop/dfs/name/current
SNN:
-rw-rw-r-- 1 hadoop hadoop 42 Nov 28 08:07 edits_0000000000000000256-0000000000000000257
-rw-rw-r-- 1 hadoop hadoop 42 Nov 28 09:07 edits_0000000000000000258-0000000000000000259
-rw-rw-r-- 1 hadoop hadoop 2874 Nov 28 08:07 fsimage_0000000000000000257
-rw-rw-r-- 1 hadoop hadoop 62 Nov 28 08:07 fsimage_0000000000000000257.md5
-rw-rw-r-- 1 hadoop hadoop 2874 Nov 28 09:07 fsimage_0000000000000000259
-rw-rw-r-- 1 hadoop hadoop 62 Nov 28 09:07 fsimage_0000000000000000259.md5
将NN的
fsimage_0000000000000000257
edits_0000000000000000258-0000000000000000259
拿到SNN,进行【合并】,生成fsimage_0000000000000000259文件,然后将此文件【推送】给NN;
同时,NN在新的编辑日志文件edits_inprogress_0000000000000000260
在紧急情况下,可辅助恢复NameNode
1 | 关于NN的补充:在大数据早期的时候,只有NN一个,假如挂了就真的挂了。 |
HDFS中的文件在物理上是分块存储,块的大小可以通过配置参数(dfs.Blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本是64M
思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率
四、MapReduce on Yarn/Yarn的工作流程
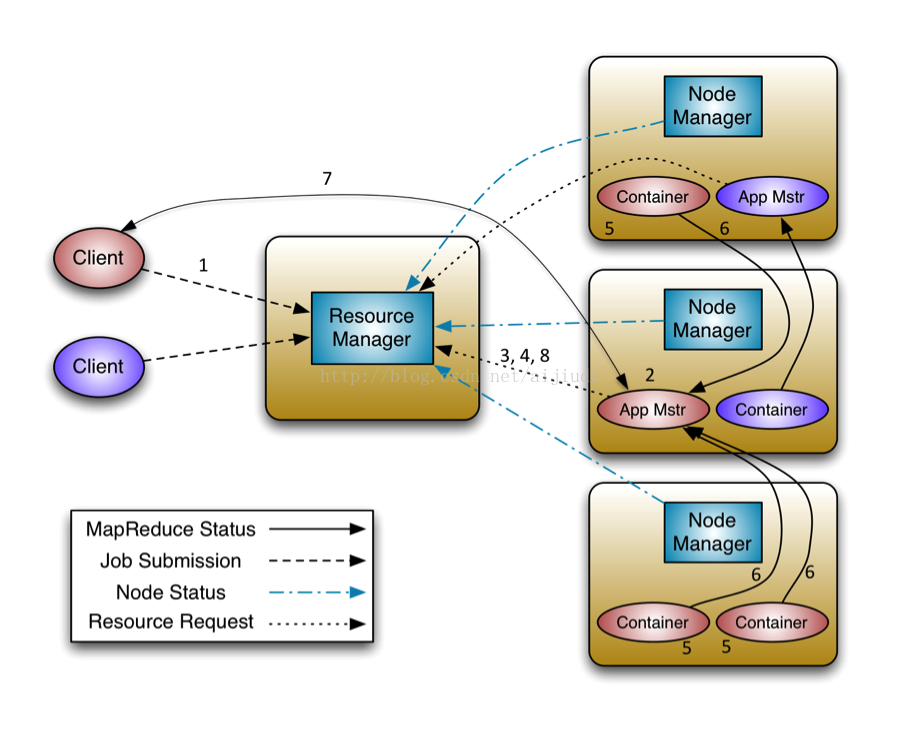
1.客户端client向ResourceManager提交应用程序/Application/作业JOB,包含application master程序,启动application master的命令等,并请求一个ApplicationMaster实例
2.RM为该job分配第一个container,与对应的NM通信,要求它在这个container启动作业的application master
3.application master向applications manager注册,这样用户就可以通过RM Web查看job的状态,一直到最后
4.application master采用轮询的方式通过【RPC】协议向resource scheduler申请和领取资源(哪台DN机器,领取多少内存 CPU)
5.一旦application master申请到资源后,与对应的NM通信,要求启动task
6.NM为任务设置好运行环境后,将任务的启动命令写到一个脚本中,并通过该脚本启动任务,运行任务
7.各个任务 task 通过【RPC】协议汇报自己的状态和进度,以让application master随时掌握各个任务的运行状态,从而在任务失败时,重启启动任务。
8.job运行完成后,application master向applications manager注销并关闭自己。
总结:
启动主程序,领取资源;1-4
运行任务,直到完成; 5-8
客户端提交job给 Applications Manager 连接Node Manager去申请一个Container的容器,这个容器运行作业的App Mstr的主程序,启动后向App Manager进行注册,然后可以访问URL界面,然后App Mastr向 Resource Scheduler申请资源,拿到一个资源的列表,和对应的NodeManager进行通信,去启动对应的Container容器,去运行 Reduce Task 和 Map Task (两个先后运行顺序随机运行),它们是向App Mstr进行汇报它们的运行状态, 当所有作业运行完成后还需要向Applications Manager进行汇报并注销和关闭
yarn中,它按照实际资源需求为每个任务分配资源,比如一个任务需要1GB内存,1个CPU,则为其分配对应的资源,而资源是用container表示的,container是一个抽象概念,它实际上是一个JAVA对象,里面有资源描述(资源所在节点,资源优先级,资源量,比如CPU量,内存量等)。当一个applicationmaster向RM申请资源时,RM会以container的形式将资源发送给对应的applicationmaster,applicationmaster收到container后,与对应的nodemanager通信,告诉它我要利用这个container运行某个任务。