[hadoop@hadoop001 ~]$ ll software/ total 805204 -rw-r--r--. 1 hadoop hadoop 395448622 Nov 21 10:03 hadoop-3.2.2.tar.gz
解压hadoop到app目录下,创建软连接
1 2 3 4 5 6 7 8
[hadoop@hadoop001 ~]$ tar -xzvf software/hadoop-3.2.2.tar.gz -C app/ [hadoop@hadoop001 ~]$ cd app [hadoop@hadoop001 app]$ [hadoop@hadoop001 app]$ ln -s /home/hadoop/app/hadoop-3.2.2 hadoop [hadoop@hadoop001 app]$ ll total 2 lrwxrwxrwx. 1 hadoop hadoop 29 Nov 25 16:28 hadoop -> /home/hadoop/app/hadoop-3.2.2 drwxr-xr-x. 9 hadoop hadoop 4096 Jan 3 2021 hadoop-3.2.2
3.查看文件目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
[hadoop@hadoop001 app]$ cd hadoop/ [hadoop@hadoop001 hadoop]$ ll total 216 drwxr-xr-x. 2 hadoop hadoop 4096 Jan 3 2021 bin #命令执行脚本 drwxr-xr-x. 3 hadoop hadoop 4096 Jan 3 2021 etc #配置文件 drwxr-xr-x. 2 hadoop hadoop 4096 Jan 3 2021 include drwxrwxr-x. 2 hadoop hadoop 4096 Nov 21 10:14 input drwxr-xr-x. 3 hadoop hadoop 4096 Jan 3 2021 lib drwxr-xr-x. 4 hadoop hadoop 4096 Jan 3 2021 libexec -rw-rw-r--. 1 hadoop hadoop 150569 Dec 5 2020 LICENSE.txt drwxrwxr-x. 2 hadoop hadoop 4096 Nov 21 10:48 logs -rw-rw-r--. 1 hadoop hadoop 21943 Dec 5 2020 NOTICE.txt drwxr-xr-x. 3 hadoop hadoop 4096 Nov 21 11:01 output -rw-rw-r--. 1 hadoop hadoop 1361 Dec 5 2020 README.txt drwxr-xr-x. 3 hadoop hadoop 4096 Jan 3 2021 sbin #启动停止脚本 drwxr-xr-x. 4 hadoop hadoop 4096 Jan 3 2021 share
大部分的大数据项目解压后目录:bin
4.手动配置Java环境变量(必须)
1
[hadoop@hadoop001 hadoop]$ vi etc/hadoop/hadoop-env.sh
1 2 3 4
# The java implementation to use. By default, this environment # variable is REQUIRED on ALL platforms except OS X! # export JAVA_HOME=/usr/java/latest export JAVA_HOME=/usr/java/jdk1.8.0_45
[hadoop@hadoop001 hadoop]$ bin/hadoop Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS] where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
buildpaths attempt to add class files from build tree --config dir Hadoop config directory --debug turn on shell script debug mode --help usage information hostnames list[,of,host,names] hosts to use in slave mode hosts filename list of hosts to use in slave mode loglevel level set the log4j level for this command workers turn on worker mode
SUBCOMMAND is one of: Admin Commands:
daemonlog get/set the log level for each daemon
Client Commands:
archive create a Hadoop archive checknative check native Hadoop and compression libraries availability classpath prints the class path needed to get the Hadoop jar and the required libraries conftest validate configuration XML files credential interact with credential providers distch distributed metadata changer distcp copy file or directories recursively dtutil operations related to delegation tokens envvars display computed Hadoop environment variables fs run a generic filesystem user client gridmix submit a mix of synthetic job, modeling a profiled from production load jar <jar> run a jar file. NOTE: please use "yarn jar" to launch YARN applications, not this command. jnipath prints the java.library.path kdiag Diagnose Kerberos Problems kerbname show auth_to_local principal conversion key manage keys via the KeyProvider rumenfolder scale a rumen input trace rumentrace convert logs into a rumen trace s3guard manage metadata on S3 trace view and modify Hadoop tracing settings version print the version
Daemon Commands:
kms run KMS, the Key Management Server
SUBCOMMAND may print help when invoked w/o parameters or with -h.
[hadoop@hadoop001 hadoop]$ vi etc/hadoop/workers hadoop001
etc/hadoop/hadoop-env.sh
1 2 3 4
[hadoop@hadoop001 hadoop]$ vi etc/hadoop/hadoop-env.sh # Where pid files are stored. /tmp by default. # export HADOOP_PID_DIR=/tmp export HADOOP_PID_DIR=/home/hadoop/tmp
7.设置SSH私钥取消密码
通过命令ssh localhost检查是否可以用ssh免密连接到localhost
成功:
1 2
[hadoop@hadoop001 hadoop]$ ssh localhost Last login: Sat Oct 9 17:05:54 2021 from localhost
[hadoop@hadoop001 hadoop]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): /home/hadoop/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: 9c:1c:53:05:cd:dc:23:1b:51:62:06:b0:92:57:66:da hadoop@hadoop001 The key's randomart image is: +--[ RSA 2048]----+ | ..BB*+ . | | . O o*.o | | o * E +. | | = + . | | S | | | | | | | | | +-----------------+ [hadoop@hadoop001 hadoop]$ ll ~/.ssh/ total 16 -rw-------. 1 hadoop hadoop 796 Nov 21 10:34 authorized_keys -rw-------. 1 hadoop hadoop 1675 Nov 25 17:04 id_rsa -rw-r--r--. 1 hadoop hadoop 398 Nov 25 17:04 id_rsa.pub -rw-r--r--. 1 hadoop hadoop 798 Nov 21 10:29 known_hosts
[hadoop@hadoop001 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+' 2021-11-25 20:10:12,608 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2021-11-25 20:10:13,702 INFO impl.MetricsConfig: Loaded properties from hadoop-metrics2.properties 2021-11-25 20:10:13,807 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 2021-11-25 20:10:13,807 INFO impl.MetricsSystemImpl: JobTracker metrics system started 2021-11-25 20:10:14,497 INFO input.FileInputFormat: Total input files to process : 9 ...... File Input Format Counters Bytes Read=232 File Output Format Counters Bytes Written=90
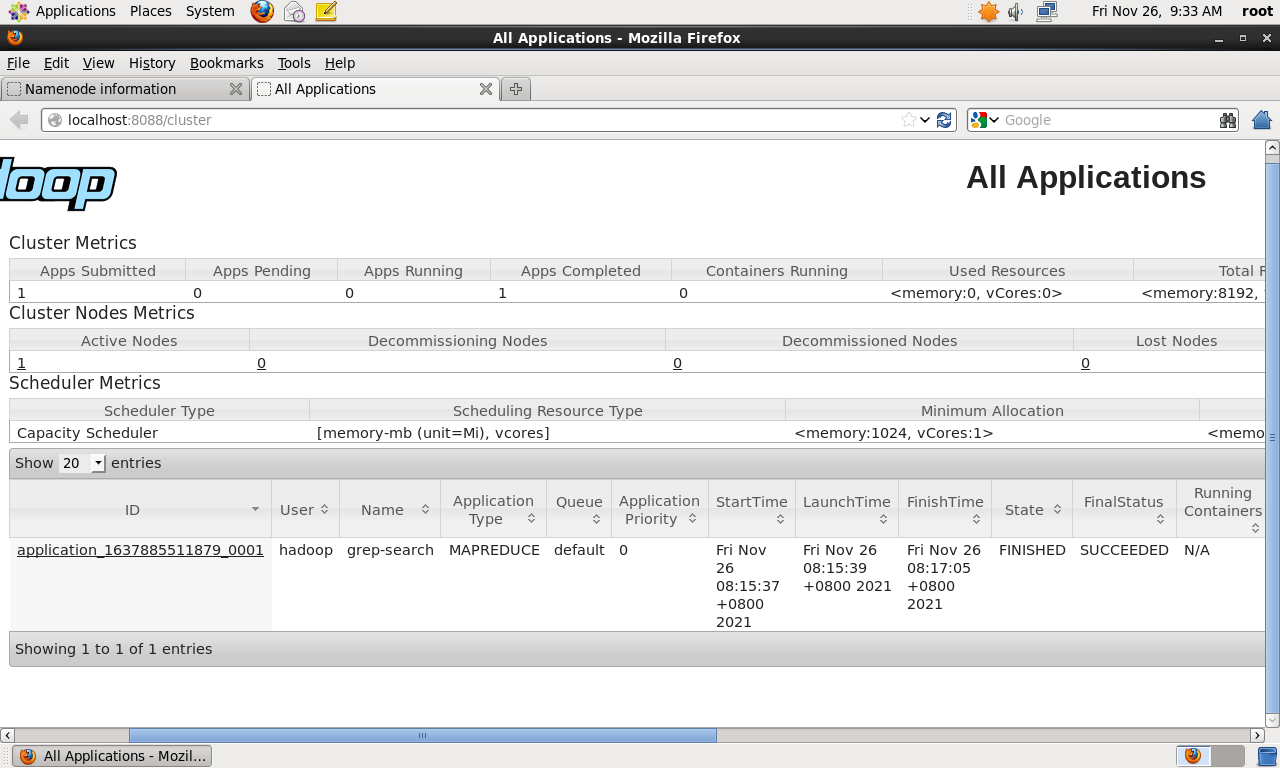
[hadoop@hadoop001 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+' 2021-11-26 08:15:32,639 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2021-11-26 08:15:34,024 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 2021-11-26 08:15:35,285 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1637885511879_0001 2021-11-26 08:15:36,280 INFO input.FileInputFormat: Total input files to process : 9 2021-11-26 08:15:36,379 INFO mapreduce.JobSubmitter: number of splits:9 2021-11-26 08:15:36,974 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1637885511879_0001 2021-11-26 08:15:36,976 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2021-11-26 08:15:37,319 INFO conf.Configuration: resource-types.xml not found 2021-11-26 08:15:37,320 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2021-11-26 08:15:37,878 INFO impl.YarnClientImpl: Submitted application application_1637885511879_0001 2021-11-26 08:15:37,945 INFO mapreduce.Job: The url to track the job: http://hadoop001:8088/proxy/application_1637885511879_0001/ 2021-11-26 08:15:37,945 INFO mapreduce.Job: Running job: job_1637885511879_0001 2021-11-26 08:15:55,539 INFO mapreduce.Job: Job job_1637885511879_0001 running in uber mode : false 2021-11-26 08:15:55,550 INFO mapreduce.Job: map 0% reduce 0% 2021-11-26 08:16:43,204 INFO mapreduce.Job: map 44% reduce 0% 2021-11-26 08:16:44,369 INFO mapreduce.Job: map 67% reduce 0% 2021-11-26 08:17:05,488 INFO mapreduce.Job: map 100% reduce 0% 2021-11-26 08:17:06,495 INFO mapreduce.Job: map 100% reduce 100% 2021-11-26 08:17:07,508 INFO mapreduce.Job: Job job_1637885511879_0001 completed successfully 2021-11-26 08:17:07,638 INFO mapreduce.Job: Counters: 55 File System Counters FILE: Number of bytes read=128 FILE: Number of bytes written=2350649 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=29993 HDFS: Number of bytes written=232 HDFS: Number of read operations=32 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Killed map tasks=1 Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=10 Total time spent by all maps in occupied slots (ms)=333545 Total time spent by all reduces in occupied slots (ms)=18937 Total time spent by all map tasks (ms)=333545 Total time spent by all reduce tasks (ms)=18937 Total vcore-milliseconds taken by all map tasks=333545 Total vcore-milliseconds taken by all reduce tasks=18937 Total megabyte-milliseconds taken by all map tasks=341550080 Total megabyte-milliseconds taken by all reduce tasks=19391488 Map-Reduce Framework Map input records=781 Map output records=4 Map output bytes=114 Map output materialized bytes=176 Input split bytes=1077 Combine input records=4 Combine output records=4 Reduce input groups=4 Reduce shuffle bytes=176 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =9 Failed Shuffles=0 Merged Map outputs=9 GC time elapsed (ms)=6070 CPU time spent (ms)=7920 Physical memory (bytes) snapshot=1882726400 Virtual memory (bytes) snapshot=27148435456 Total committed heap usage (bytes)=1269469184 Peak Map Physical memory (bytes)=211144704 Peak Map Virtual memory (bytes)=2715578368 Peak Reduce Physical memory (bytes)=106315776 Peak Reduce Virtual memory (bytes)=2720391168 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=28916 File Output Format Counters Bytes Written=232 2021-11-26 08:17:07,682 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://hadoop001:9000/user/hadoop/output already exists at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:164) at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:277) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:143) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1565) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1562) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1562) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1583) at org.apache.hadoop.examples.Grep.run(Grep.java:94) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76) at org.apache.hadoop.examples.Grep.main(Grep.java:103) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at org.apache.hadoop.util.RunJar.run(RunJar.java:323) at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
5.停止服务
1 2 3 4 5
[hadoop@hadoop001 hadoop]$ stop-yarn.sh Stopping nodemanagers localhost: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9 Stopping resourcemanager [hadoop@hadoop001 hadoop]$ jps