
我们在分布式存储原理总结中了解了分布式存储的三大特点:
- 数据分块,分布式的存储在多台机器上
- 数据块冗余存储在多台机器以提高数据块的高可用性
- 遵从主/从(master/slave)结构的分布式存储集群
HDFS作为分布式存储的实现,肯定也具有上面3个特点。
HDFS数据块
与一般文件系统一样,HDFS也有块(block)的概念,HDFS上的文件也被划分为块大小的多个分块作为独立的存储单元。与通常的磁盘文件系统不同的是:
HDFS中小于一个块大小的文件不会占据整个块的空间(当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB)
在Hadoop1当中,文件的block块默认大小是64M,Hadoop2当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件(dfs.block.size)进行指定。
设置数据块的好处
(1)一个文件的大小可以大于集群任意节点磁盘的容量
(2)容易对数据进行备份,提高容错能力
(3)使用抽象块概念而非整个文件作为存储单元,大大简化存储子系统的设计
块缓存
通常DataNode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在DataNode的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过在缓存块的DataNode上运行任务,可以利用块缓存的优势提高读操作的性能。
HDFS分布式存储
在HDFS中,数据块默认的大小是128M,当我们往HDFS上上传一个300多M的文件的时候,那么这个文件会被分成3个数据块:
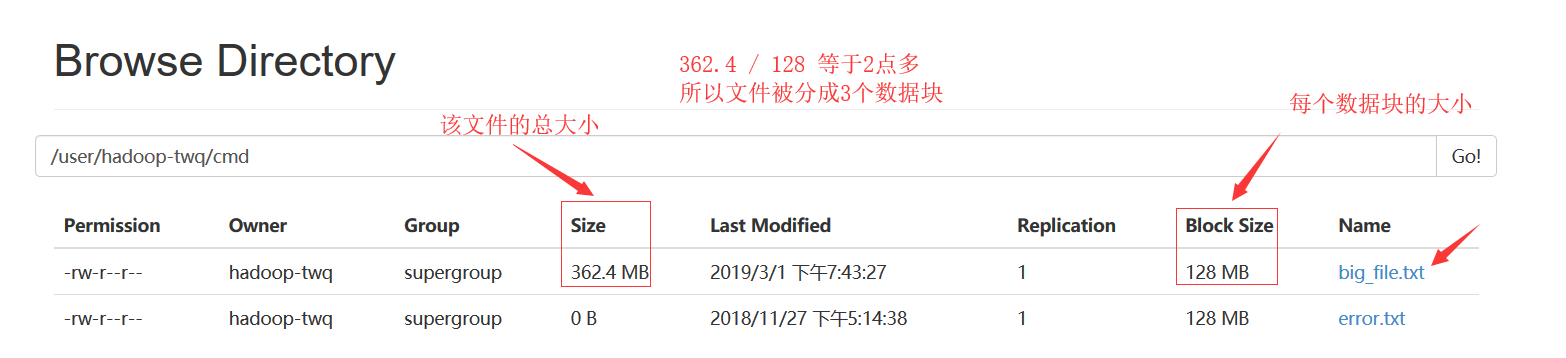
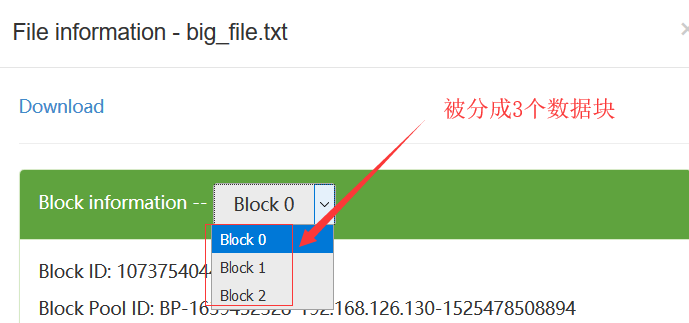
所有的数据块是分布式的存储在所有的DataNode上:
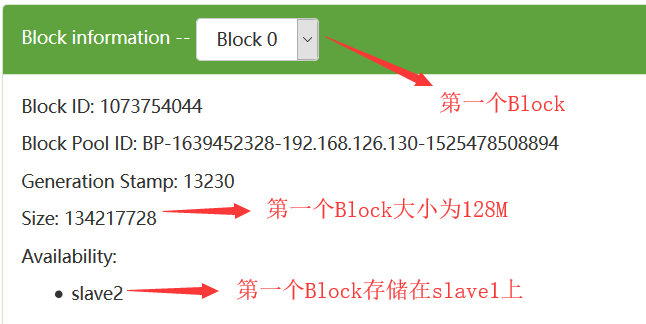
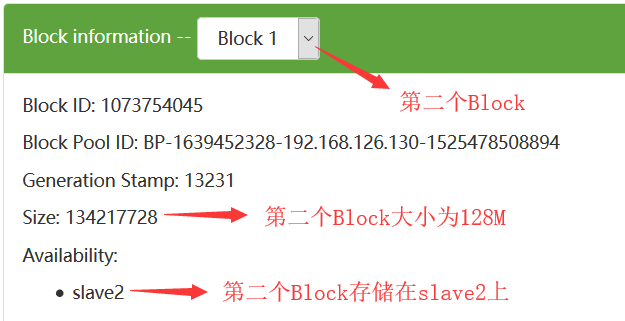
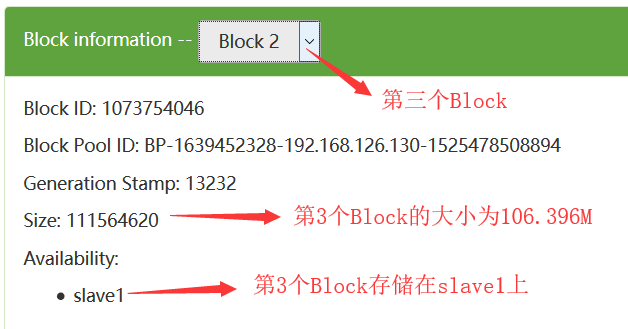
为了提高每一个数据块的高可用性,在HDFS中每一个数据块默认备份存储3份,在这里我们看到的只有1份,是因为我们在hdfs-site.xml中配置了如下的配置:
1 | <property> |
我们也可以通过如下的命令,将文件/user/hadoop-twq/cmd/big_file.txt的所有的数据块都备份存储3份:
1 | hadoop fs -setrep 3 /user/hadoop-twq/cmd/big_file.txt |
我们可以从如下可以看出:每一个数据块都冗余存储了3个备份
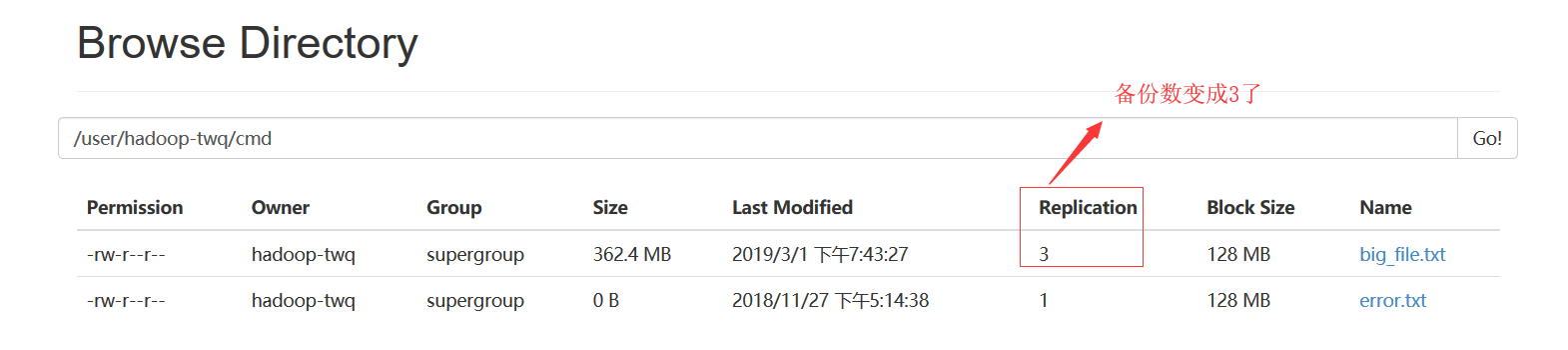
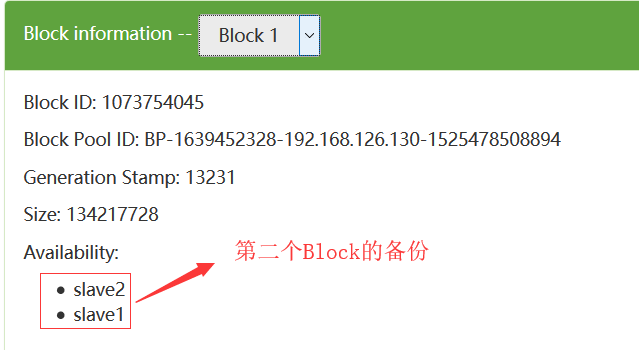
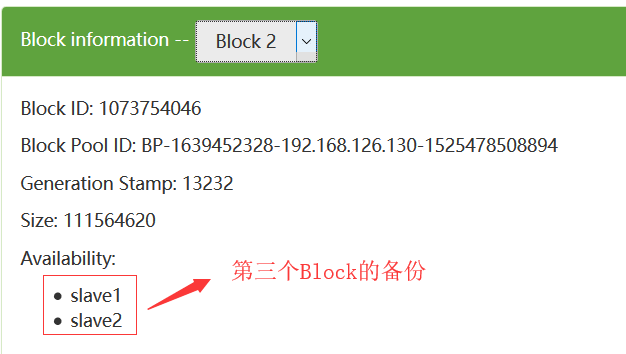
在这里,可能会问这里为什么看到的是2个备份呢?这个是因为我们的集群只有2个DataNode,所以最多只有2个备份,即使你设置成3个备份也没用,所以我们设置的备份数一般都是比集群的DataNode的个数相等或者要少
一定要注意:当我们上传362.4MB的数据到HDFS上后,如果数据块的备份数是3个话,那么在HDFS上真正存储的数据量大小是:362.4MB * 3 = 1087.2MB
注意:我们上面是通过HDFS的WEB UI来查看HDFS文件的数据块的信息,除了这种方式查看数据块的信息,我们还可以通过命令fsck来查看
问题:HDFS里面为什么一般设置块大小为64MB或128MB?
为什么不能远少于64MB?
(1)减少硬盘寻道时间。HDFS设计前提是应对大数据量操作,若数据块大小设置过小,那需要读取的数据块数量就会增多,从而间接增加底层硬盘的寻道时间
“HDFS的块比磁盘块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间可以明显大于定位这个块开始位置所需的时间。这样,传输一个由多个块组成的文件的时间就取决于磁盘传输速率。”
“我们做一个估计计算,如果寻址时间为10ms左右,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们需要设置块大小为100MB左右。而默认的块大小实际为64MB,但是很多情况下HDFS使用128MB的块设置。以后随着新一代磁盘驱动器传输速率的提升,块的大小将被设置得更大。”
(2)减少NameNode内存消耗。由于NameNode记录着DataNode中的数据块信息,若数据块大小设置过小,则数据块数量增多,需要维护的数据块信息就会增多,从而消耗NameNode的内存。
为什么不能远大于64MB?
原因主要从上层的MapReduce框架来寻找。
(1)Map崩溃问题。系统需要重新启动,启动过程中需要重新加载数据,数据块越大,数据加载时间越长,系统恢复过程越长
(2)监管时间问题。主节点监管其他节点的情况,每个节点会周期性的与主节点进行汇报通信。倘若某一个节点保持沉默的时间超过一个预设的时间间隔,主节点会记录这个节点状态为死亡,并将该节点的数据转发给别的节点。而这个“预设时间间隔”是从数据块的角度大致估算的。(加入对64MB的数据块,我可以假设你10分钟之内无论如何也能解决完了吧,超过10分钟还没反应,那我就认为你出故障或已经死了。)64MB大小的数据块,其时间尚可较为精准地估计,如果我将数据块大小设为640MB甚至上G,那这个“预设的时间间隔”便不好估算,估长估短对系统都会造成不必要的损失和资源浪费。
(3)问题分解问题。数据量的大小与问题解决的复杂度呈线性关系。对于同一个算法,处理的数据量越大,时间复杂度越高。
(4)约束Map输出。在Map Reduce框架里,Map之后的数据是要经过排序才执行Reduce操作的。这通常涉及到归并排序,而归并排序的算法思想便是“对小文件进行排序,然后将小文件归并成大文件”,因此“小文件”不宜过大。
“但是,该参数也不会设置得过大。MapReduce中的map任务通常一次处理一个块中的数据,因此,如果任务数太少(少于集群中的节点数量),作业的运行速度就会变慢。”
数据块的实现
在HDFS的实现中,数据块被抽象成类org.apache.hadoop.hdfs.protocol.Block(我们以下简称Block)。在Block类中有如下几个属性字段:
1 | public class Block implements Writable, Comparable<Block> { |
我们从WEB UI上的数据块信息也可以看到:
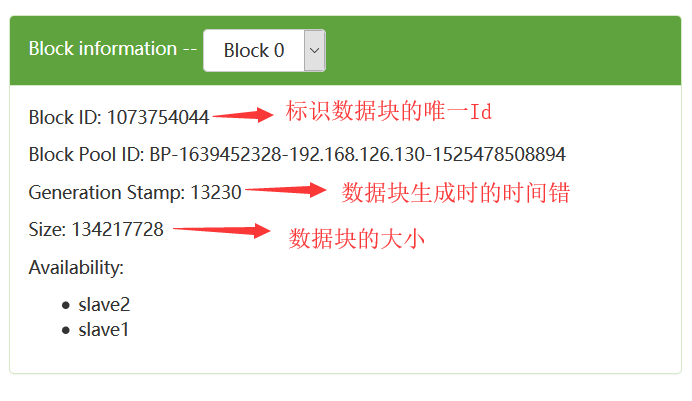
一个Block除了存储上面的3个字段信息,还需要知道这个Block含有多少个备份,每一个备份分别存储在哪一个DataNode上,为了存储这些信息,HDFS中有一个名为
org.apache.hadoop.hdfs.server.blockmanagement.BlockInfoContiguous(下面我们简称为BlockInfo)
的类来存储这些信息,这个BlockInfo类继承Block类,如下:
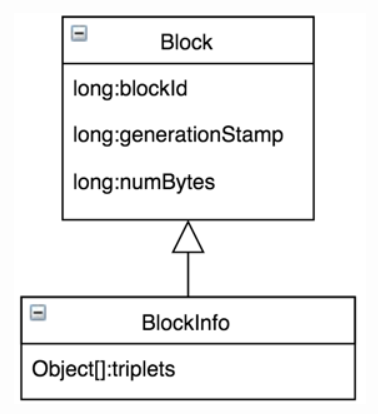
BlockInfo类中只有一个非常核心的属性,就是名为triplets的数组,这个数组的长度是3*replication,replication表示数据块的备份数。这个数组中存储了该数据块所有的备份数据块对应的DataNode信息,我们现在假设备份数是3,那么这个数组的长度是3*3=9,这个数组存储的数据如下:

也就是说,triplets包含的信息:
- triplets[i]:Block所在的DataNode;
- triplets[i+1]:该DataNode上前一个Block;
- triplets[i+2]:该DataNode上后一个Block;
其中i表示的是Block的第i个副本,i取值[0,replication)。
我们在HDFS的NameNode中的Namespace管理中讲到了,一个HDFS文件包含一个BlockInfo数组,表示这个文件分成的若干个数据块,这个BlockInfo数组实际上就是我们这里说的BlockInfoContiguous数组。以下是INodeFile的属性:
1 | public class INodeFile { |
那么,到现在为止,我们了解到了这些信息:文件包含了哪些Block,这些Block分别被实际存储在哪些DataNode上,DataNode上所有Block前后链表关系。
如果从信息完整度来看,以上信息数据足够支持所有关于HDFS文件系统的正常操作,但还存在一个使用场景较多的问题:怎样通过blockId快速定位BlockInfo?
我们其实可以在NameNode上用一个HashMap来维护blockId到Block的映射,也就是说我们可以使用HashMap<Block, BlockInfo>来维护,这样的话我们就可以快速的根据blockId定位BlockInfo,但是由于在内存使用、碰撞冲突解决和性能等方面存在问题,Hadoop团队之后使用重新实现的LightWeightGSet代替HashMap,该数据结构本质上也是利用链表解决碰撞冲突的HashTable,但是在易用性、内存占用和性能等方面表现更好。
HDFS为了解决通过blockId快速定位BlockInfo的问题,所以引入了BlocksMap,BlocksMap底层通过LightWeightGSet实现。
在HDFS集群启动过程,DataNode会进行BR(BlockReport,其实就是将DataNode自身存储的数据块上报给NameNode),根据BR的每一个Block计算其HashCode,之后将对应的BlockInfo插入到相应位置逐渐构建起来巨大的BlocksMap。前面在INodeFile里也提到的BlockInfo集合,如果我们将BlocksMap里的BlockInfo与所有INodeFile里的BlockInfo分别收集起来,可以发现两个集合完全相同,事实上BlocksMap里所有的BlockInfo就是INodeFile中对应BlockInfo的引用;通过Block查找对应BlockInfo时,也是先对Block计算HashCode,根据结果快速定位到对应的BlockInfo信息。至此涉及到HDFS文件系统本身元数据的问题基本上已经解决了。
BlocksMap内存估算
HDFS将文件按照一定的大小切成多个Block,为了保证数据可靠性,每个Block对应多个副本,存储在不同DataNode上。NameNode除需要维护Block本身的信息外,还需要维护从Block到DataNode列表的对应关系,用于描述每一个Block副本实际存储的物理位置,BlocksMap结构即用于Block到DataNode列表的映射关系,BlocksMap是常驻在内存中,而且占用内存非常大,所以对BlocksMap进行内存的估算是非常有必要的。
BlocksMap的内部结构:
以下的内存估算是在64位操作系统上且没有开启指针压缩功能场景下
1 | class BlocksMap { |
可以得出BlocksMap的直接内存大小是:对象头16字节 + 4字节 + 8字节 = 28字节
Block的结构如下:
1 | public class Block implements Writable, Comparable<Block> { |
可以得出Block的直接内存大小是:对象头16字节 + 8字节 + 8字节 + 8字节 = 40字节
BlockInfoContiguous的结构如下:
1 | public class BlockInfoContiguous extends Block { |
可以得出BlockInfoContiguous的直接内存大小是:对象头16字节 + 8字节 + 8字节 + 104字节 = 136字节
LightWeightGSet的结构如下:
1 | public class LightWeightGSet<K, E extends K> implements GSet<K, E> { |
LightWeightGSet本质是一个链式解决冲突的哈希表,为了避免rehash过程带来的性能开销,初始化时,LightWeightGSet的索引空间直接给到了整个JVM可用内存的2%,并且不再变化。 所以LightWeightGSet的直接内存大小为:**对象头16字节 + 32字节 + 4字节 + 4字节 + 4字节 + (2%JVM可用内存) = 60字节 + (2%JVM可用内存)
假设集群中共1亿Block,NameNode可用内存空间固定大小128GB,则BlocksMap占用内存情况:
1 | BlocksMap直接内存大小 + (Block直接内存大小 + BlockInfoContiguous直接内存大小) * 100M + LightWeightGSet直接内存大小 |
上面为什么是乘以100M呢? 因为100M = 100 * 1024 * 1024 bytes = 104857600 bytes,约等于1亿字节,而上面的内存的单位都是字节的,我们乘以100M,就相当于1亿Block
BlocksMap数据在NameNode整个生命周期内常驻内存,随着数据规模的增加,对应Block数会随之增多,BlocksMap所占用的JVM堆内存空间也会基本保持线性同步增加。
参考: