
HDFS文件写流程
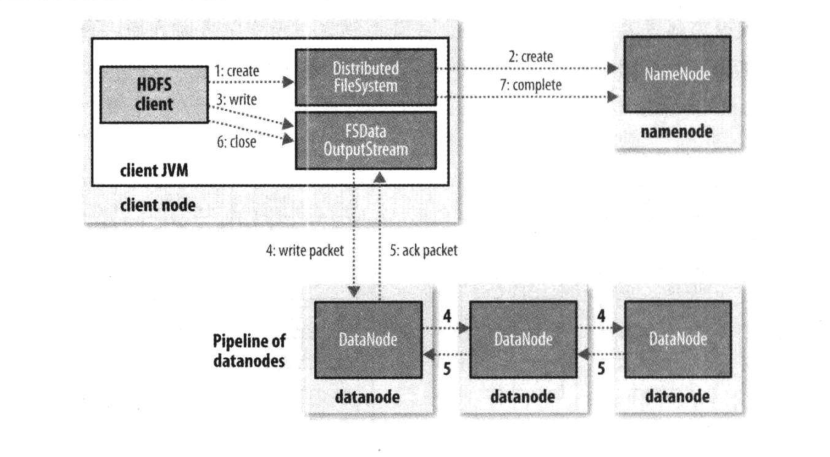
客户端调用FileSystem.create(filePath)方法新建文件,但此时文件中还没有相应的数据块。
DFS和NN进行【RPC】通信,NN会去检查这个文件是否已经存在、是否有权限创建这个文件等一系列校验操作;
如果校验通过,就会为创建新文件记录一条记录,告知DFS向客户端返回一个【FsDataOutputStream】对象
如果校验失败,文件创建失败并向客户端抛出一个IOException异常。
Client 调用【FsDataOutputStream】对象的write方法,将数据分成一个个的数据包,并写入【数据队列】。
【DataStreamer】处理数据队列,根据文件的大小、当前集群的块大小、副本数和当前的DN节点情况计算出这个文件要上传多少个块(包含副本)和块上传到哪些DN节点,要求NN分配新的数据块。这一组选定的DN构成【管线】。
根据【副本放置策略】,【DataStreamer】处理数据队列,将数据包传输到【管线】中DN1,DN1存储并将它发送到DN2,DN2存储并将它发送到DN3。
【FsDataOutputStream】也维护一个【确认队列】等待确认回执,当三个副本写完的时候,DN3就返回一个ack package确认包给DN2,DN2接收到并加上自己的确认信息到ack package确认包DN1,DN1接收到并加上自己的确认信息到ack package确认包给【FsDataOutputStream】,告诉它三个副本都写完了,数据包才会从【确认队列】删除。
当所有的块全部写完,Client调用【FsDataOutputStream】对象的close方法,关闭输出流。
再次调用FileSystem.complete方法,告诉NN文件写成功。
HDFS文件读流程
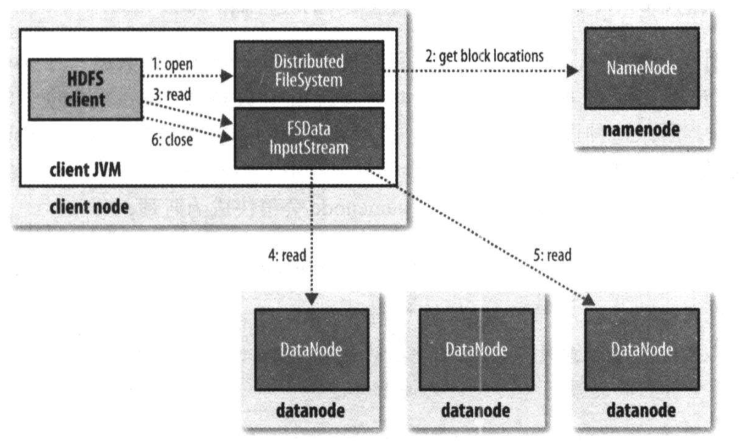
Client调用FileSystem的open(filePath)方法,打开希望读取的文件
DFS与NN进行【RPC】通信,确定文件的起始位置。NN返回这个文件的部分或者全部的block列表(DN会根据他们与客户端的距离排序,如果客户端本身就是一个DN,则会从本地DN读取数据)
DFS给Client返回一个【FSDataInputStream】对象。
Client调用【FSDataInputStream】对象的read方法,开始读取数据
连接最近的存储要读取文件中第一个块的DN进行读取,读取完成后会校验是否完整
- 假如ok就关闭与DN通信。
- 假如不ok,就记录块和DN的信息,通知NN,保证以后不会反复读取该节点后续的块,会尝试从这个块的另一个邻近节点读取。
然后连接最近的第二个块所在的DN进行读取,以此类推。
假如当block的列表全部读取完成,文件还没结束,再去NN请求下一个批次的block列表。
(整个过程对于客户端都是透明的,在客户端看来它一直读取一个连续的流)
一旦Client完成读取,调用【FSDataInputStram】对象的close方法,关闭输入流。
HDFS副本放置策略
Hadoop的默认布局策略是在运行客户端的节点上放第1个复本(如果客户端运行在集群之外,就随机的选择一个节点,但是系统会避免挑选那些存储太满或太忙的节点)。第2个复本放在与第1个不同且是随机选择的另外的机架中的节点上。第3个复本与第2个复本放在同一个机架上面,且是随机选择的一个节点,其他的复本放在集群中随机选择的节点上面,但是系统会尽量避免在相同的机架上面放太多的复本。
一旦选定了复本的放置的位置,就会根据网络拓扑创建一个管线,如下图为一个典型的复本管线:
总的来说,这一方法不仅提供了很好的稳定性,数据不容易丢失(数据块存储在两个机架中)同时实现了很好的负载均衡,包括写入宽带(写入操作只要遍历一个交换机),读取性能(可以从两个机架中进行选择读取)和集群中块的均匀分布(客户端只在本地机架写入一个块)。
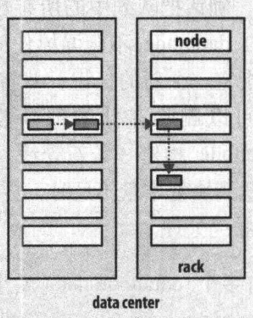
生产上进行读写,尽量自己选取DN节点。(减少网络IO)
第一个副本:放在Client所处的节点上。如果客户端在集群外,则放在随机调选的一台不太忙的DN上。
第二个副:放置在和第一个副本不相同的机架的随机节点上。
第三个副本:放置在和第二个副本位于相同机架的不同节点上。
假如还有更多副本:随机放。
但是,生产上真的是这样的吗?这样会带来 权限问题,比如一不小心把Linux文件删除了怎么办
所以生产上真正的是,有个单点的客户端节点,不是NN也不是DN进程在。
其实网络IO只是小问题,一般生产上集群内部都是万兆带宽,光纤的。忽略不计。