
一、Hadoop支持LZO压缩
1.lzop
lzo格式文件压缩解压需要用到服务器的lzop工具,hadoop 的native库(hadoop checknative是没有的lzo,zip相关信息)并不支持
1 | #安装以前先执行以下命令 |
【注意】这代表你已经有lzop,如果找不到,就执行以下命令
1 | #若没有执行如下安装命令【这些命令一定要在root用户下安装,否则没有权限】 |
2.安装hadoop-lzo
下载
1
wget https://github.com/twitter/hadoop-lzo/archive/master.zip
解压
1
2
3
4
5
6
7
8
9
10
11
12[hadoop@hadoop001 source]$ ll
total 1028
drwxrwxr-x. 18 hadoop hadoop 4096 Oct 13 20:53 hadoop-2.6.0-cdh5.7.0
drwxr-xr-x. 18 hadoop hadoop 4096 Jan 3 2021 hadoop-3.2.2-src
-rw-rw-r--. 1 hadoop hadoop 1040294 Jan 11 21:57 master
[hadoop@hadoop001 source]$ unzip master
[hadoop@hadoop001 source]$ ll
total 1028
drwxrwxr-x. 18 hadoop hadoop 4096 Oct 13 20:53 hadoop-2.6.0-cdh5.7.0
drwxr-xr-x. 18 hadoop hadoop 4096 Jan 3 2021 hadoop-3.2.2-src
drwxrwxr-x. 5 hadoop hadoop 4096 Jan 11 22:03 hadoop-lzo-master
-rw-rw-r--. 1 hadoop hadoop 1040294 Jan 11 21:57 master修改pom.xml
1
2
3[hadoop@hadoop001 source]cd hadoop-lzo-master
[hadoop@hadoop001 hadoop-lzo-master]$ vi pom.xml
<hadoop.current.version>3.2.2</hadoop.current.version>声明两个临时环境变量
1
2
3
4[hadoop@hadoop001 hadoop-lzo-master]$
export C_INCLUDE_PATH=/home/hadoop/app/hadoop/lzo/include
[hadoop@hadoop001 hadoop-lzo-master]$
export LIBRARY_PATH=/home/hadoop/app/hadoop/lzo/lib编译(不需要阿里云仓库)
1
[hadoop@hadoop001 hadoop-lzo-master]$ mvn clean package -Dmaven.test.skip=true
查看编译后的jar,hadoop-lzo-0.4.21-SNAPSHOT.jar则为我们需要的jar
1
2
3
4
5
6
7
8
9
10
11
12
13
14[hadoop@hadoop001 hadoop-lzo-master]$ cd target/
[hadoop@hadoop001 target]$ ll
total 444
drwxrwxr-x. 2 hadoop hadoop 4096 Jan 11 22:03 antrun
drwxrwxr-x. 4 hadoop hadoop 4096 Jan 11 22:03 apidocs
drwxrwxr-x. 5 hadoop hadoop 4096 Jan 11 22:03 classes
drwxrwxr-x. 3 hadoop hadoop 4096 Jan 11 22:03 generated-sources
-rw-rw-r--. 1 hadoop hadoop 180550 Jan 11 22:03 hadoop-lzo-0.4.21-SNAPSHOT.jar
-rw-rw-r--. 1 hadoop hadoop 181006 Jan 11 22:03 hadoop-lzo-0.4.21-SNAPSHOT-javadoc.jar
-rw-rw-r--. 1 hadoop hadoop 52043 Jan 11 22:03 hadoop-lzo-0.4.21-SNAPSHOT-sources.jar
drwxrwxr-x. 2 hadoop hadoop 4096 Jan 11 22:03 javadoc-bundle-options
drwxrwxr-x. 2 hadoop hadoop 4096 Jan 11 22:03 maven-archiver
drwxrwxr-x. 3 hadoop hadoop 4096 Jan 11 22:03 native
drwxrwxr-x. 3 hadoop hadoop 4096 Jan 11 22:03 test-classes上传jar包
将hadoop-lzo-0.4.21-SNAPSHOT.jar包复制到我们的hadoop的$HADOOP_HOME/share/hadoop/common/目录下才能被hadoop使用
1
[hadoop@hadoop001 target]$ cp hadoop-lzo-0.4.21-SNAPSHOT.jar ~/app/hadoop/share/hadoop/common/
如果是集群,需要使用
xsync hadoop-lzo-0.4.21.jar命令同步到集群中的其他机器修改配置文件
core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>mapred-site.xml(如果修改了,则默认输出格式为lzo)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>com.hadoop.compression.lzo.LzopCodec</value>
</property>测试
配置了mapred-site.xml:
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /input /output
没有配置mapred-site.xml(指定输出文件格式为lzo):
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
1
2
3
4[hadoop@hadoop001 mapreduce]$ hadoop jar /home/hadoop/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /wc/input/wc.data /output
[hadoop@hadoop001 mapreduce]$ hadoop fs -ls /output
-rw-r--r-- 1 hadoop supergroup 0 2022-01-11 22:18 /output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 95 2022-01-11 22:18 /output/part-r-00000.lzo
3.LZO创建索引
创建LZO文件的索引
创建LZO文件的索引,LZO压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO压缩文件创建索引。若无索引,则LZO文件的切片只有一个。
命令:
hadoop jar $HADOOP_HOME/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer XXX.lzo执行wc(没有创建索引)
创建需要分片处理的bigwcneedspilt.data.lzo(203M)文件,并上传到hdfs上
1
2
3
4
5
6
7
8[hadoop@hadoop001 data]$ lzop bigwcneedspilt.data
[hadoop@hadoop001 data]$ du -sh bigwc*
157M bigwc.data
51M bigwc.data.lzo
625M bigwcneedspilt.data
203M bigwcneedspilt.data.lzo
18M bigwc.txt
[hadoop@hadoop001 data]$ hadoop fs -put bigwcneedspilt.data.lzo /user/hadoop/data/执行wc(没有创建索引)
1
[hadoop@hadoop001 ~]$ hadoop jar /home/hadoop/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /user/hadoop/data/bigwcneedspilt.data.lzo /output1
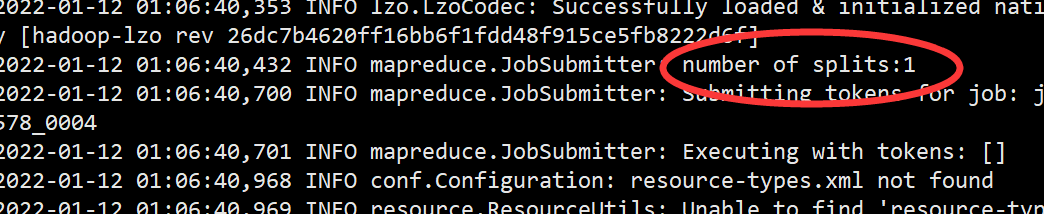
可以看到此时切片并没有生效,依然只有一个
对上传的LZO文件创建索引
1
[hadoop@hadoop001 ~]$ hadoop jar /home/hadoop/app/hadoop/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.DistributedLzoIndexer /user/hadoop/data/bigwcneedspilt.data.lzo

执行wc(已经创建索引)
1
[hadoop@hadoop001 ~]$ hadoop jar /home/hadoop/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /user/hadoop/data/bigwcneedspilt.data.lzo /output2

此时已经成功切片
二、Hive支持处理LZO压缩格式的数据的统计查询
开启压缩的方式
- 在**
$HIVE_HOME/conf/hive-site.xml**中设置
1 | <!-- 设置hive语句执行输出文件是否开启压缩,具体的压缩算法和压缩格式取决于hadoop中 |
在hive中开启
查看默认状态:
1
2
3
4hive (hive)> SET hive.exec.compress.output;
hive.exec.compress.output=false
hive (hive)> set mapreduce.output.fileoutputformat.compress.codec;
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec开启支持压缩,格式为lzop(lzo在文件构建索引后才会支持数据分片):
1
2hive (hive)> SET hive.exec.compress.output=true;
hive (hive)> SET mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec;
数据与环境准备
数据准备:
1 | [hadoop@hadoop001 data]$ lzop bigemp.data |
为了方便测试分片,我重启了hadoop,修改了hdfs-site.xml设置了blocksize=10M。然后mapr-site.xml没有配置上面的4个值。
1 | <property> |
未开启(未添加索引)
建表
1 | CREATE TABLE big_emp (id int,name string,dept string) |
从本地load LZO压缩数据bigemp.data.lzo到表big_emp
1 | LOAD DATA LOCAL INPATH '/home/hadoop/data/bigemp.data.lzo' OVERWRITE INTO TABLE big_emp |
查看大小

查询统计测试
1 | select count(1) from big_emp; |
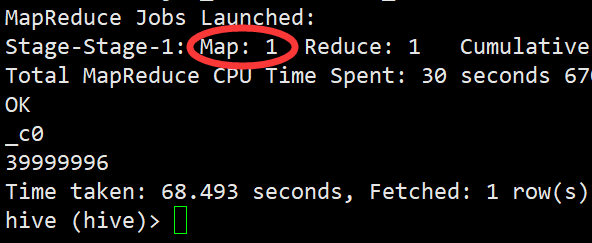
因为我们的块大小是默认的128M,而bigemp.data.lzo这个lzo压缩文件的大小远远大于128M*1.1,但是我们可以看见Map只有一个,可见lzo是不支持分片的。
已开启(已添加索引)
开启压缩
生成的压缩文件格式必须为设置为LzopCodec,lzoCode的压缩文件格式后缀为.lzo_deflate是无法创建索引的。
1 | hive (hive)> SET hive.exec.compress.output=true; |
建表,并插入big_emp的数据
(若不是直接load的lzo文件,需要开启压缩,且压缩格式为LzopCodec,load数据并不能改变文件格式和压缩格式。):
1 | CREATE TABLE big_emp_split ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' |
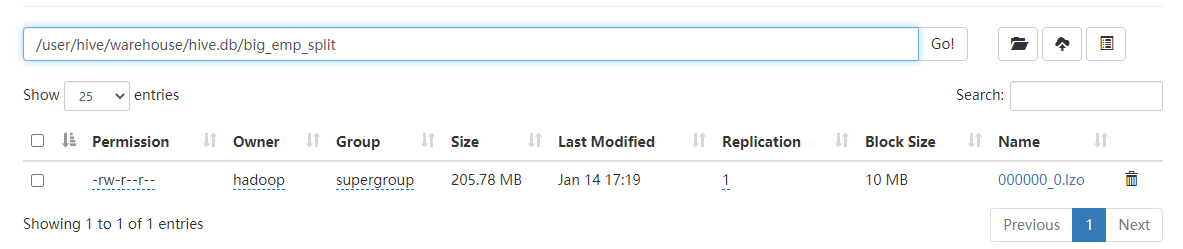
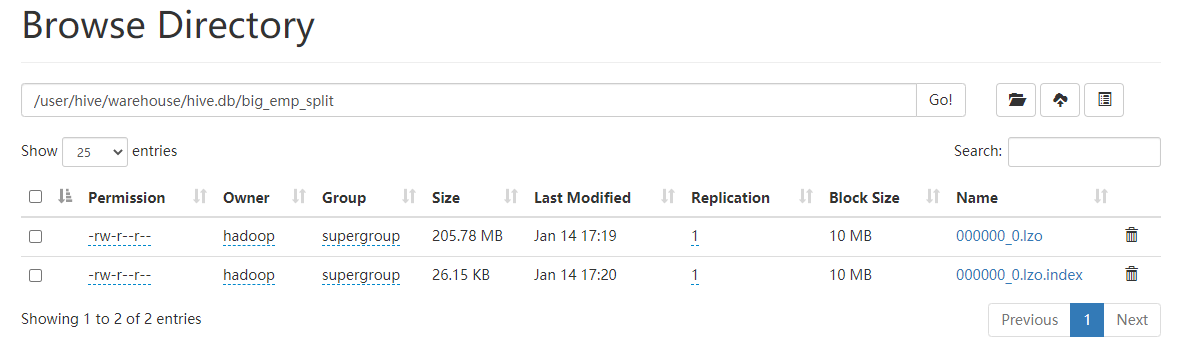
构建LZO文件索引
1 | hadoop jar /home/hadoop/app/hadoop/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.LzoIndexer /user/hive/warehouse/hive.db/big_emp_split |
查询统计测试
1 | select count(1) from big_emp_split; |
当做到这步,遇到好几个问题:
直接返回结果,没有启动MR
1
2
3
4
5hive (hive)> select count(1) from big_emp_split;
OK
_c0
39999996
Time taken: 0.27 seconds, Fetched: 1 row(s)可能是有缓存,添加where条件可以运行MR程序。
当设置
SET mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec;后,count(1)报错。设置成
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec;可以运行成功。但结果比未生成索引时的多了几条,map数量仍然为1,即生成索引后仍然没有分片成功。推断是把索引文件作为输入了,所以数据变多。网上查阅,应该是因为把索引文件当成小文件合并了,所以map数量为1,且数据变多。解决办法:修改
CombineHiveInputFormat为HiveInputFormat。1
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
参考:https://blog.csdn.net/weixin_43589563/article/details/122353909
问题解决,分片成功。
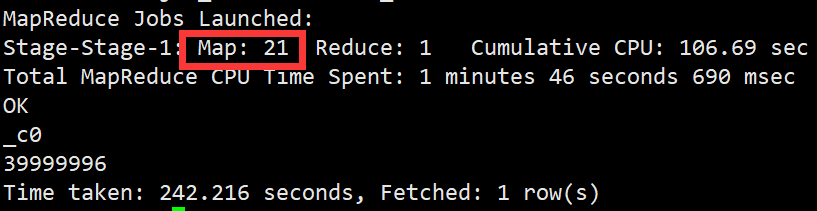
这里我们可以看到map数量是21,也就是说lzo压缩文件构建索引以后是支持分片的。
补充
这个开启压缩,在生成表的时候需要(生成lzo文件),在做统计的时候不需要设置。lzo文件生成索引后,索引不被合并掉,就支持分片。
Hive支持处理LZO压缩格式分片步骤
默认设置即可
1
2SET hive.exec.compress.output=false;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec更改hive.input.format,防止索引被合并
1
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
为lzo文件创建索引
1
hadoop jar /home/hadoop/app/hadoop/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar com.hadoop.compression.lzo.LzoIndexer /user/hive/warehouse/hive.db/big_emp_split
统计查询