
https://spark.apache.org/docs/latest/building-spark.html
本机环境:
hadoop:3.2.2
jdk:1.8+
scala:2.12.14
hive:2.3.9(spark中默认版本)
一、下载
https://spark.apache.org/downloads.html
二、解压并导入IDEA
三、编译
修改配置
通过Add Frameworks Support添加Scala2.12支持。
执行命令配置Maven:
export MAVEN_OPTS="-Xss64m -Xmx2g -XX:ReservedCodeCacheSize=1g"修改pom.xml
版本参数
scala:2.12.14【2处】
1
<scala.version>2.12.14</scala.version>
hadoop : 3.2.2【1处】
1
<hadoop.version>3.2.2</hadoop.version>
hive:默认,不指定hive版本
其他(否则报错):
1
2
3
4
5<dependency>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
</dependency>修改make-distribution.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23#VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | tail -n 1)
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ \
# | grep -v "INFO"\
# | grep -v "WARNING"\
# | fgrep --count "<id>hive</id>";\
# # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
# # because we use "set -o pipefail"
# echo -n)
VERSION=3.2.0 # spark 版本
SCALA_VERSION=2.12 # scala 版本
SPARK_HADOOP_VERSION=3.2.2 #对应的hadoop 版本
SPARK_HIVE=1 # 支持的hive
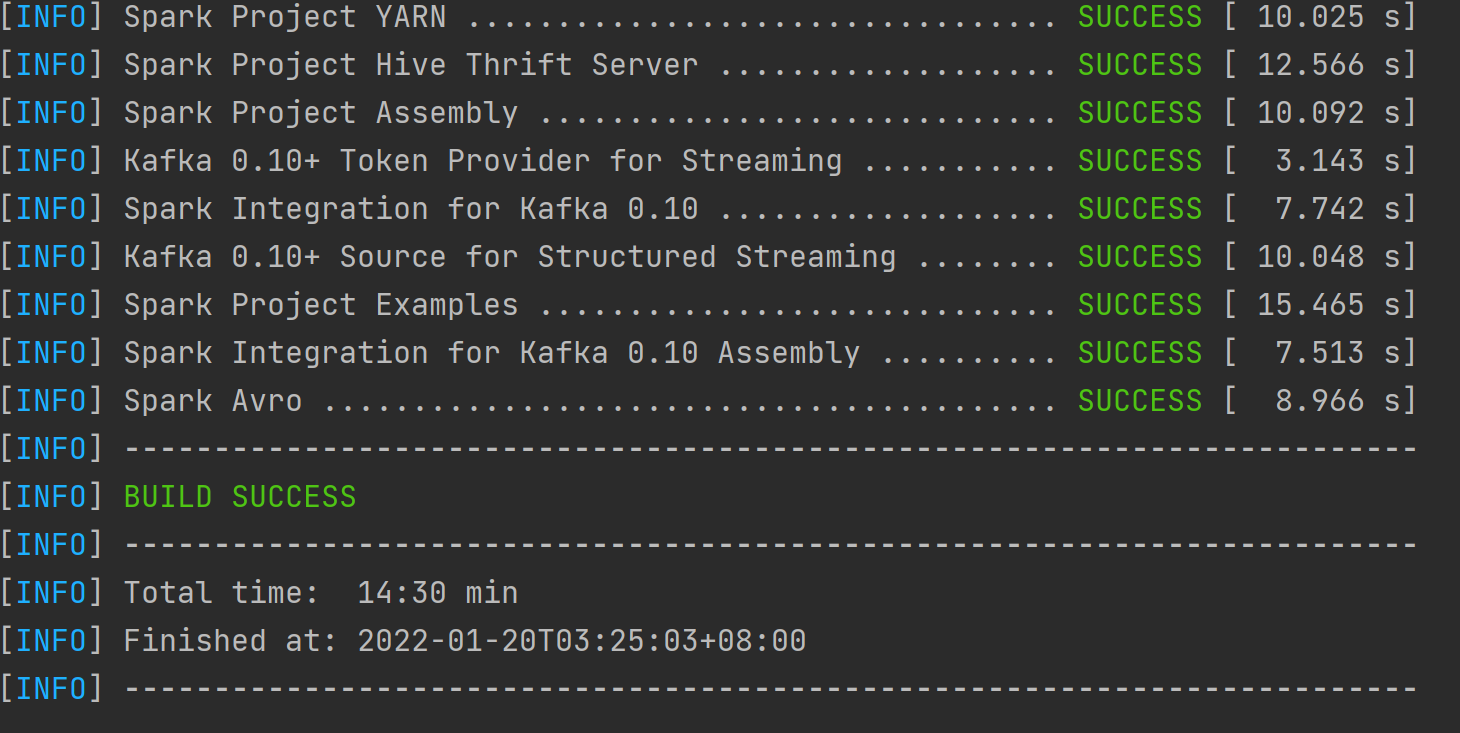
编译
1
dev/make-distribution.sh --name custom-spark --pip --r --tgz -Psparkr -Pyarn -Phadoop-3.2.2 -Phive -Phive-thriftserver -Pmesos -Dhadoop.version=3.2.2
添加jar包和Scala SDK依赖,导入模块
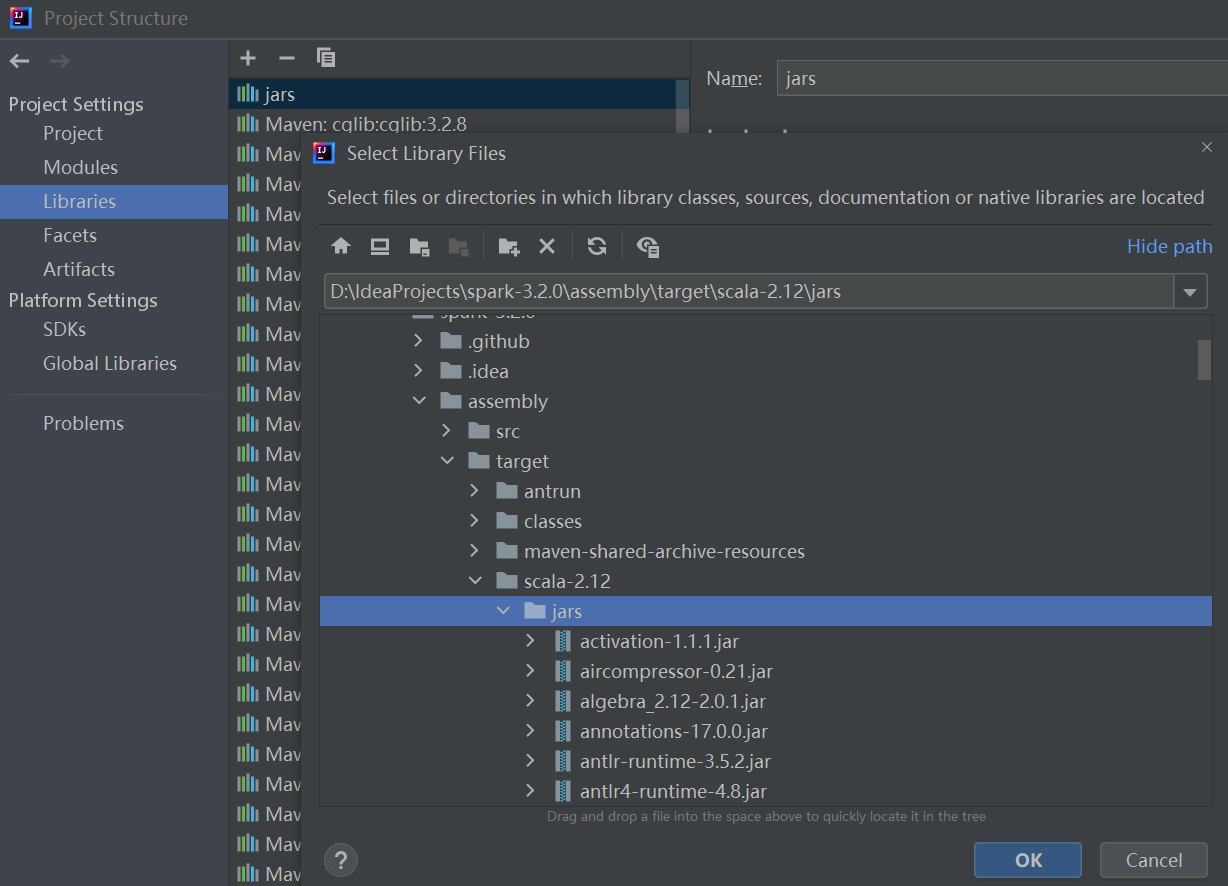
jar包位置:
./assembly/target/scala-2.12(这个包包含了Spark编译得到的jar包,以及编译过程中所依赖的包。)添加依赖:
使用MAVEN的Generate Sources and Update Folders For All Projects
Project Structure–>Libraries–> 添加Scala SDK
Project Structure–>Libraries–> 添加jar包
SparkSQL和Hive集成
SparkSQL需要的是Hive表的元数据,将hive的hive-site.xml文件复制到spark的conf文件夹中。hadoop的配置文件也一并放到conf文件夹中
启动hadoop和hive的metastore服务
1
2start-all.sh
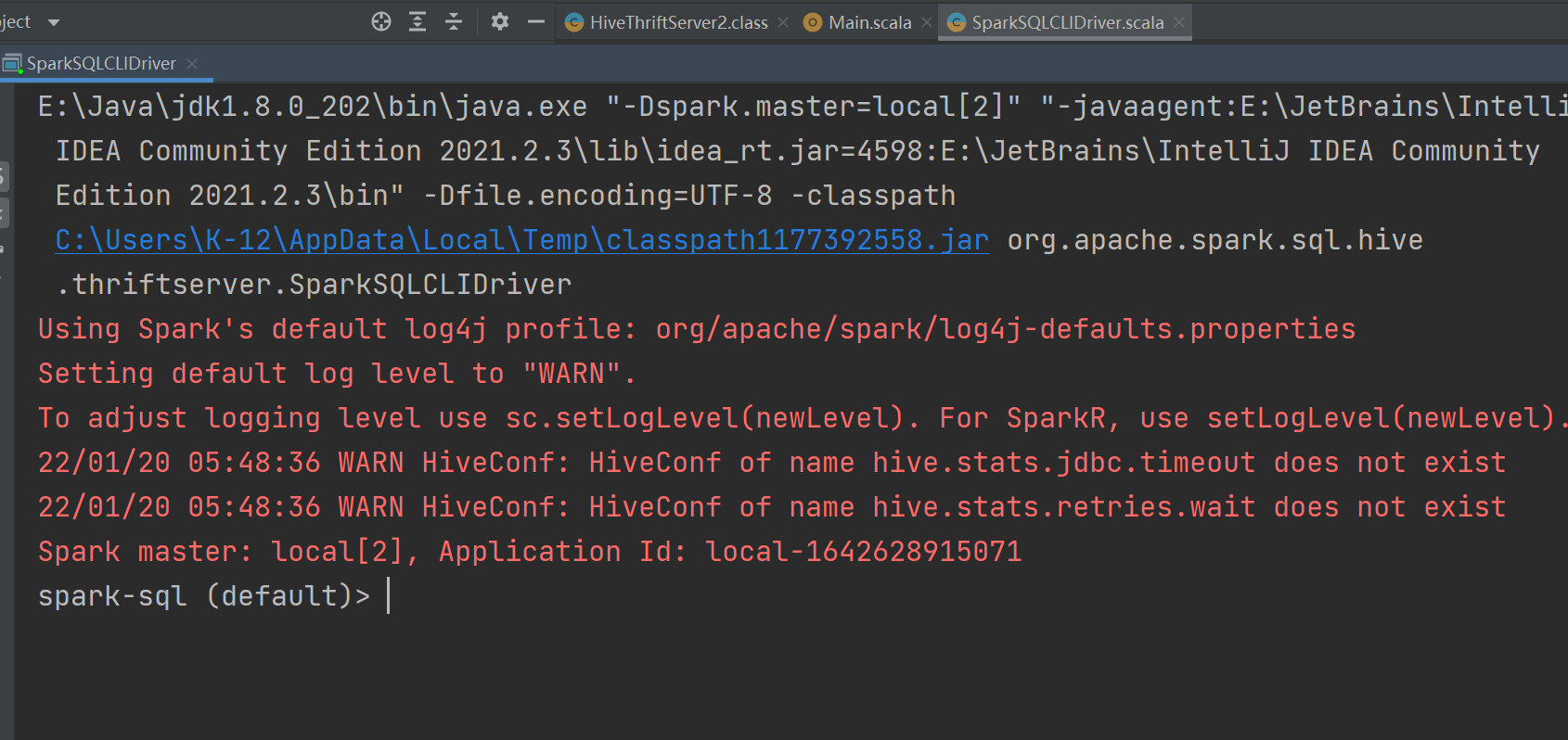
hive --service metastore &找到spark-sql的入口程序:
org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver配置VM options
VM options:
-Dscala.usejavacp=true
-Dspark.master=local[2]
-Djline.WindowsTerminal.directConsole=false
启动程序:
测试
执行查询
1
2use hive;
select e.empno,e.ename,e.deptno,d.dname from emp e join dept d on e.deptno=d.deptno;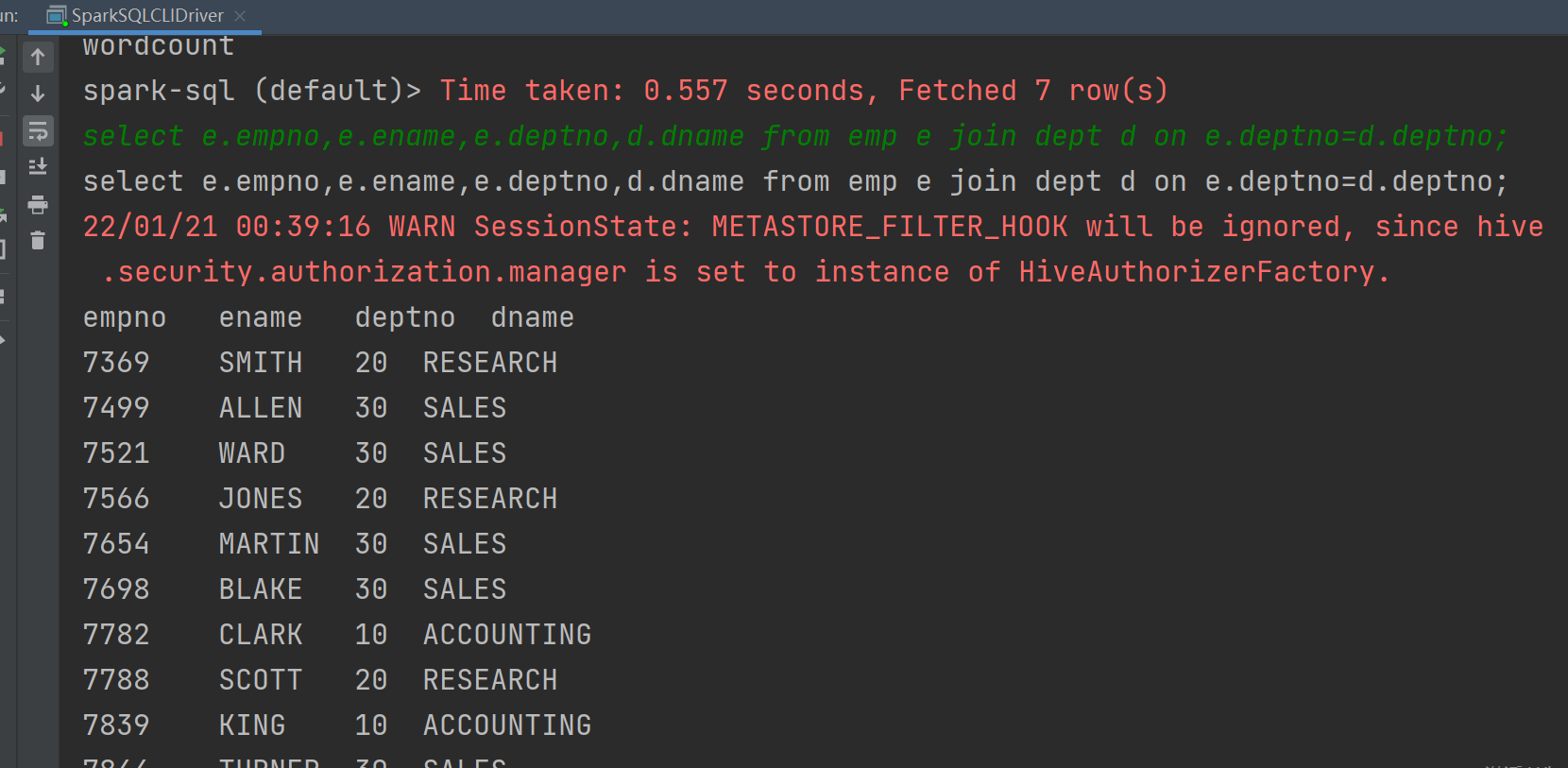
四、期间遇到的问题
Classnotfound
解决方法:导入jar包
运行,报错:

解决方法:配置VM options:
-Dscala.usejavacp=true运行,报错:
org.apache.spark.SparkException: A master URL must be set in your configuration解决方法:配置VM options:
-Dspark.master=local[2]spark-sql启动成功,但输入命令后没反应
以下提示信息可忽略,主要是程序阻塞了导致没反应。
1
WARN SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
解决方法:配置VM options:
-Djline.WindowsTerminal.directConsole=false