

Hive起源于Facebook(一个美国的社交服务网络)。Facebook有着大量的数据,而Hadoop是一个开源的MapReduce实现,可以轻松处理大量的数据。但是MapReduce程序对于Java程序员来说比较容易写,但是对于其他语言使用者来说不太方便。此时Facebook最早地开始研发Hive,它让对Hadoop使用SQL查询(实际上SQL后台转化为了MapReduce)成为可能,那些非Java程序员也可以更方便地使用。hive最早的目的也就是为了分析处理海量的日志。
什么是 Hive?
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL Extract-Transform-Load),也可以叫做数据清洗,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HiveQL,它允许熟悉 SQL 的用户查询数据。
Hive 不是
- 一个关系数据库
- 一个设计用于联机事务处理(OLTP)
- 实时查询和行级更新的语言
Hive特点
- 它存储架构在一个数据库中并处理数据到HDFS。
- 它是专为联机分析处理(OLAP)设计。
- 它提供SQL类型语言查询叫HiveQL或HQL。
- 它是低学习成本,快速和可扩展的。
适用场景
Hive在Hadoop中扮演数据仓库的角色,主要用于静态的结构以及需要经常分析的工作。
Hive 构建在基于静态(离线)批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,****Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的离线批处理作业,例如,网络日志分析。
Hive架构
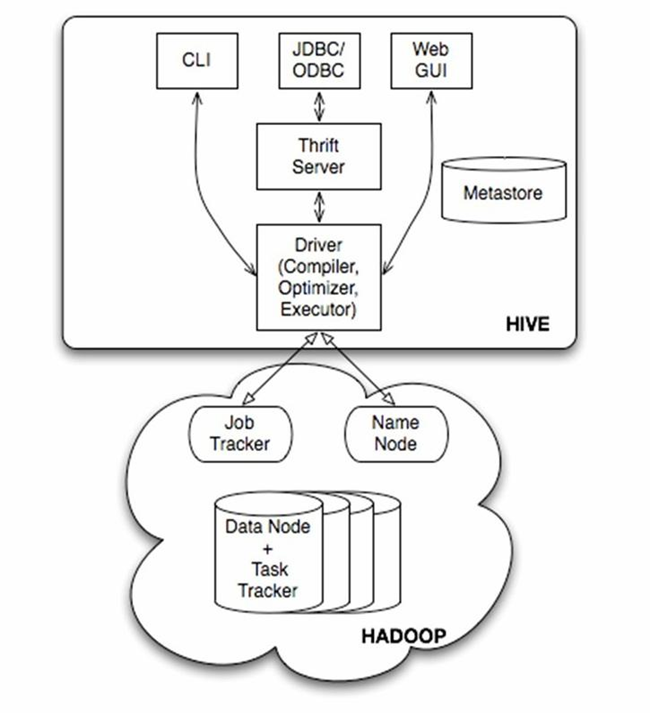
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor),这些组件我可以分为两大类:服务端组件和客户端组件。
2.1服务端组件:
Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。元数据对于hive十分重要,因此hive支持把metastore服务独立出来,安装到远程的服务器集群里,从而解耦hive服务和metastore服务,保证hive运行的健壮性.
Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
2.2客户端组件:
CLI:command line interface,命令行接口。
Thrift客户端:上面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。
详解metastore:
Hive的metastore组件是hive元数据集中存放地。Metastore组件包括两个部分:metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。Metastore服务是建立在后台数据存储介质之上,并且可以和hive服务进行交互的服务组件,默认情况下,metastore服务和hive服务是安装在一起的,运行在同一个进程当中。我也可以把metastore服务从hive服务里剥离出来,metastore独立安装在一个集群里,hive远程调用metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的metastore服务,可以让metastore服务和hive服务运行在不同的进程里,这样也保证了hive的稳定性,提升了hive服务的效率。
Hive详细运行架构
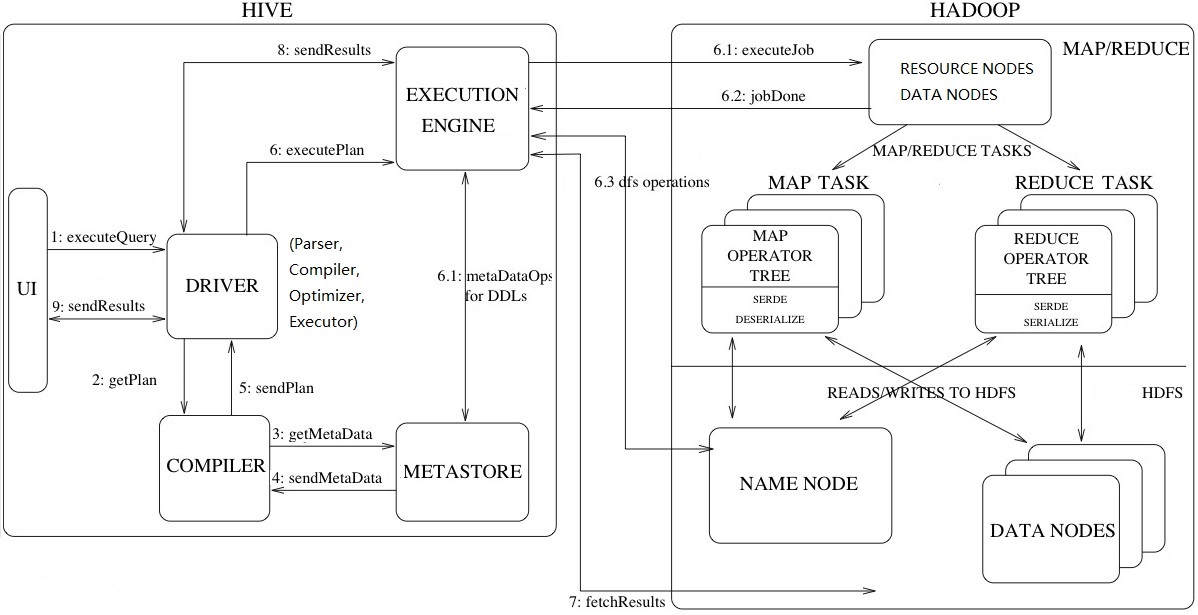
工作流程步骤:
ExecuteQuery(执行查询操作):命令行或Web UI之类的Hive接口将查询发送给Driver(任何数据驱动程序,如JDBC、ODBC等)执行;
GetPlan(获取计划任务):Driver借助编译器解析查询,检查语法和查询计划或查询需求;
GetMetaData(获取元数据信息):编译器将元数据请求发送到Metastore(任何数据库);
SendMetaData(发送元数据):MetaStore将元数据作为对编译器的响应发送出去;
SendPlan(发送计划任务):编译器检查需求并将计划重新发送给Driver。到目前为止,查询的解析和编译已经完成;
ExecutePlan(执行计划任务):Driver将执行计划发送到执行引擎;
6.1 ExecuteJob(执行Job任务):在内部,执行任务的过程是MapReduce Job。执行引擎将Job发送到ResourceManager,ResourceManager位于Name节点中,并将job分配给datanode中的NodeManager。在这里,查询执行MapReduce任务;
6.1 Metadata Ops(元数据操作):在执行的同时,执行引擎可以使用Metastore执行元数据操作;
6.2 jobDone(完成任务):完成MapReduce Job;
6.3 dfs operations(dfs操作记录):向namenode获取操作数据;
FetchResult(拉取结果集):执行引擎将从datanode上获取结果集;
SendResults(发送结果集至driver):执行引擎将这些结果值发送给Driver;
SendResults (driver将result发送至interface):Driver将结果发送到Hive接口(即UI);
Driver端的Hive编译流程
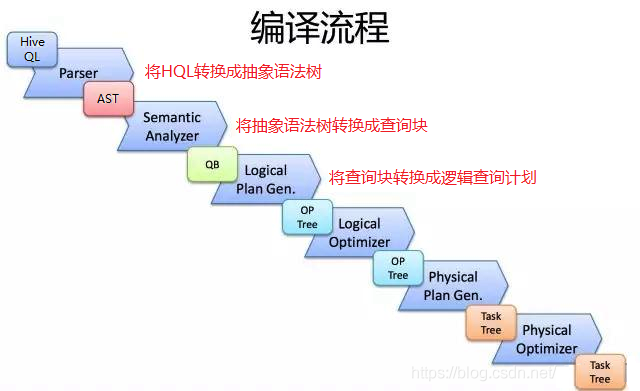
Hive是如何将SQL转化成MapReduce任务的,整个编辑过程分为六个阶段:
- 词法分析/语法分析:使用Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL语句解析成抽象语法树(AST Tree);
- 语义分析:遍历AST Tree,抽象出查询的基本组成单元QueryBlock,并从Metastore获取模式信息,验证SQL语句中队表名、列名,以及数据类型(即QueryBlock)的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF);
- 逻辑计划生成:遍历QueryBlock,翻译生成执行操作树Operator Tree(即逻辑计划);
- 逻辑计划优化:逻辑层优化器对Operator Tree进行变换优化,合并不必要的ReduceSinkOperator,减少shuffle数据量;
- 物理计划生成:将Operator Tree(逻辑计划)生成包含由MapReduce任务组成的DAG的物理计划——任务树;
- 物理计划优化:物理层优化器对MapReduce任务树进行优化,并进行MapReduce任务的变换,生成最终的执行计划;
Hive的元数据存储
对于数据存储,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图。Hive中包含以下数据模型:Table内部表,External Table外部表,Partition分区,Bucket桶。Hive默认可以直接加载文本文件,还支持sequence file、RCFile。
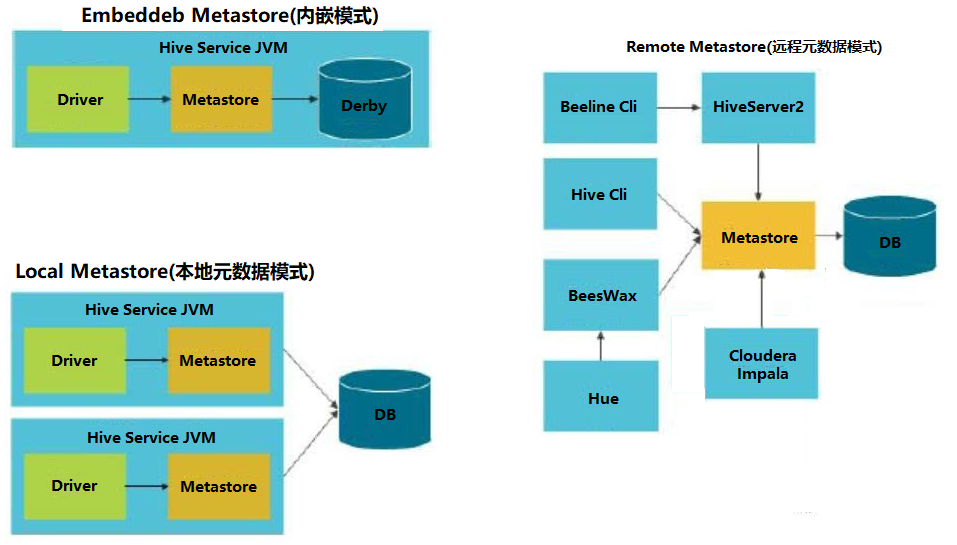
Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库:
元数据内嵌模式(Embedded Metastore Database)
此模式连接到一个本地内嵌In-memory的数据库Derby,一般用于Unit Test,内嵌的derby数据库每次只能访问一个数据文件,也就意味着它不支持多会话连接。
| 参数 | 描述 | 用例 |
|---|---|---|
| javax.jdo.option.ConnectionURL | JDBC连接url | jdbc:derby:databaseName=metastore_db;create=true |
| javax.jdo.option.ConnectionDriverName | JDBC driver名称 | org.apache.derby.jdbc.EmbeddedDriver |
| javax.jdo.option.ConnectionUserName | 用户名 | xxx |
| javax.jdo.option.ConnectionPassword | 密码 | xxxx |
本地元数据存储模式(Local Metastore Server)
通过网络连接到一个数据库中,是最经常使用到的模式。
| 参数 | 描述 | 用例 |
|---|---|---|
| javax.jdo.option.ConnectionURL | JDBC连接url | jdbc:mysql:// |
| javax.jdo.option.ConnectionDriverName | JDBC driver名称 | com.mysql.jdbc.Driver |
| javax.jdo.option.ConnectionUserName | 用户名 | xxx |
| javax.jdo.option.ConnectionPassword | 密码 | xxxx |
远程访问元数据模式(Remote Metastore Server)
用于非Java客户端访问元数据库,在服务端启动MetaServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。

服务端启动HiveMetaStore
第一种方式:
1
hive --service metastore -p 9083 &
第二种方式:
如果在hive-site.xml里指定了hive.metastore.uris的port,就可以不指定端口启动了
1
2
3
4<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>1
hive --service metastore
- 客户端配置
| 参数 | 描述 | 用例 |
|---|---|---|
| hive.metastore.uris | metastore server的url | thrift:// |
| hive.metastore.local | metastore server的位置 | false表示远程 |
三种模式汇总
与RDBMS对比
RDBMS是什么
RDBMS 是 Relational Database Management System 的缩写,中文译为“关系数据库管理系统”,它是 SQL 语言以及所有现代数据库系统(例如 SQL Server、DB2、Oracle、MySQL 和 Microsoft Access)的基础。
在 RDBMS 中,数据被存储在一种称为表(Table)的数据库对象中,它和 Excel 表格类似,都由许多行(Row)和列(Column)构成。每一行都是一条数据,每一列都是数据的一个属性,整个表就是若干条相关数据的集合。
对比
| 对比项 | Hive | RDBMS |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Row Device or Local FS |
| 执行器 | MapReduce | Executor |
| 数据插入 | 支持批量导入/单挑插入 | 支持单条或批量导入 |
| 数据更新 | 不支持 | 支持 |
| 处理数据规模 | 大 | 小 |
| 执行延迟 | 高(构建在HDFS和MR之上) | 低 |
| 分区 | 支持 | 支持 |
| 索引 | 0.8版本之后加入索引 | 有复杂的索引 |
| 扩展性 | 高(好) | 有限(差) |
| 事务 | 不支持(插件下支持,不推荐) | 支持 |
| 应用场景 | 海量数据查询 | 实时查询 |
Below are the key features of Hive that differ from RDBMS.
Hive resembles a traditional database by supporting SQL interface but it is not a full database. Hive can be better called as data warehouse instead of database.
Hive enforces schema on read time whereas RDBMS enforces schema on write time.
In RDBMS, a table’s schema is enforced at data load time, If the data being
loaded doesn’t conform to the schema, then it is rejected. This design is called schema on write.But Hive doesn’t verify the data when it is loaded, but rather when a
it is retrieved. This is called schema on read.Schema on read makes for a very fast initial load, since the data does not have to be read, parsed, and serialized to disk in the database’s internal format. The load operation is just a file copy or move.
Schema on write makes query time performance faster, since the database can index columns and perform compression on the data but it takes longer to load data into the database.
Hive is based on the notion of Write once, Read many times but RDBMS is designed for Read and Write many times.
In RDBMS, record level updates, insertions and deletes, transactions and indexes are possible. Whereas these are not allowed in Hive because Hive was built to operate over HDFS data using MapReduce, where full-table scans are the norm and a table update is achieved by transforming the data into a new table.
In RDBMS, maximum data size allowed will be in 10’s of Terabytes but whereas Hive can 100’s Petabytes very easily.
As Hadoop is a batch-oriented system, Hive doesn’t support OLTP (Online Transaction Processing) but it is closer to OLAP (Online Analytical Processing) but not ideal since there is significant latency between issuing a query and receiving a reply, due to the overhead of Mapreduce jobs and due to the size of the data sets Hadoop was designed to serve.
RDBMS is best suited for dynamic data analysis and where fast responses are expected but Hive is suited for data warehouse applications, where relatively static data is analyzed, fast response times are not required, and when the data is not changing rapidly.
To overcome the limitations of Hive, HBase is being integrated with Hive to support record level operations and OLAP.
Hive is very easily scalable at low cost but RDBMS is not that much scalable that too it is very costly scale up.
总结:
Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。Hive是建立在Hadoop之上的数据仓库软件工具,它提供了一系列的工具,帮助用户对大规模的数据进行提取、转换和加载,即通常所称的ETL(Extraction,Transformation,and Loading)操作。Hive可以直接访问存储在HDFS或者其他存储系统(如Hbase)中的数据,然后将这些数据组织成表的形式,在其上执行ETL操作。 Hive的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
参考链接:
https://www.cnblogs.com/swordfall/p/13426569.html