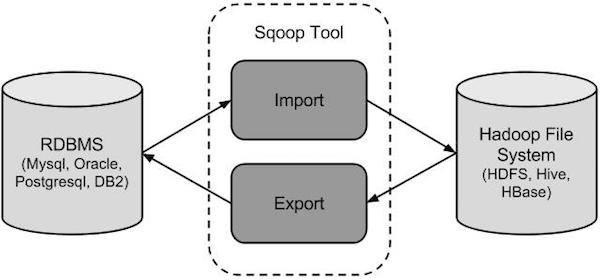
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
[hadoop@hadoop001 lib]$ sqoop list-databases --connect jdbc:mysql://hadoop001:3306 --username root --password '123456' Warning: /home/hadoop/app/sqoop/../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /home/hadoop/app/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /home/hadoop/app/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /home/hadoop/app/sqoop/../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 2022-02-27 23:54:08,530 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 2022-02-27 23:54:08,647 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2022-02-27 23:54:08,832 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. Sun Feb 27 23:54:09 GMT 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. information_schema mysql performance_schema sys
问题小结
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils
[hadoop@hadoop001 ~]$ sqoop list-databases --connect jdbc:mysql://hadoop001:3306 --username root --password '123456' Warning: /home/hadoop/app/sqoop/../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /home/hadoop/app/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /home/hadoop/app/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /home/hadoop/app/sqoop/../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 2022-02-27 23:25:34,723 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 2022-02-27 23:25:34,838 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2022-02-27 23:25:35,007 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils at org.apache.sqoop.manager.MySQLManager.initOptionDefaults(MySQLManager.java:73) at org.apache.sqoop.manager.SqlManager.<init>(SqlManager.java:89) at com.cloudera.sqoop.manager.SqlManager.<init>(SqlManager.java:33) at org.apache.sqoop.manager.GenericJdbcManager.<init>(GenericJdbcManager.java:51) at com.cloudera.sqoop.manager.GenericJdbcManager.<init>(GenericJdbcManager.java:30) at org.apache.sqoop.manager.CatalogQueryManager.<init>(CatalogQueryManager.java:46) at com.cloudera.sqoop.manager.CatalogQueryManager.<init>(CatalogQueryManager.java:31) at org.apache.sqoop.manager.InformationSchemaManager.<init>(InformationSchemaManager.java:38) at com.cloudera.sqoop.manager.InformationSchemaManager.<init>(InformationSchemaManager.java:31) at org.apache.sqoop.manager.MySQLManager.<init>(MySQLManager.java:65) at org.apache.sqoop.manager.DefaultManagerFactory.accept(DefaultManagerFactory.java:67) at org.apache.sqoop.ConnFactory.getManager(ConnFactory.java:184) at org.apache.sqoop.tool.BaseSqoopTool.init(BaseSqoopTool.java:272) at org.apache.sqoop.tool.ListDatabasesTool.run(ListDatabasesTool.java:44) at org.apache.sqoop.Sqoop.run(Sqoop.java:147) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76) at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243) at org.apache.sqoop.Sqoop.main(Sqoop.java:252) Caused by: java.lang.ClassNotFoundException: org.apache.commons.lang.StringUtils at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) ... 20 more [hadoop@hadoop001 ~]$
[hadoop@hadoop001 ~]$ sqoop help 2022-03-01 16:31:57,832 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop COMMAND [ARGS]
Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information
See 'sqoop help COMMAND' for information on a specific command.
列出数据库list-databases
1 2 3 4 5 6 7 8 9 10 11 12
[hadoop@hadoop001 ~]$ sqoop list-databases --connect jdbc:mysql://hadoop001:3306?useSSL=false --username root --password '123456' 2022-02-28 10:35:17,817 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 2022-02-28 10:35:17,972 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2022-02-28 10:35:18,212 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. information_schema azkaban hive hue mysql performance_schema ruozedata sys
[hadoop@hadoop001 ~]$ sqoop help import usage: sqoop import [GENERIC-ARGS] [TOOL-ARGS]
Common arguments: --connect <jdbc-uri> Specify JDBC connect string --connection-manager <class-name> Specify connection manager class name --connection-param-file <properties-file> Specify connection parameters file --driver <class-name> Manually specify JDBC driver class to use --hadoop-home <hdir> Override $HADOOP_MAPRED_HOME_ARG --hadoop-mapred-home <dir> Override $HADOOP_MAPRED_HOME_ARG --help Print usage instructions --metadata-transaction-isolation-level <isolationlevel> Defines the transaction isolation level for metadata queries. For more details check java.sql.Connection javadoc or the JDBC specificaiton --oracle-escaping-disabled <boolean> Disable the escaping mechanism of the Oracle/OraOop connection managers -P Read password from console --password <password> Set authentication password --password-alias <password-alias> Credential provider passwor alias --password-file <password-file> Set authentication password file path --relaxed-isolation Use read-uncommitted isolation for imports --skip-dist-cache Skip copying jars to distributed cache --temporary-rootdir <rootdir> Defines the temporary root directory for the import --throw-on-error Rethrow a RuntimeException on error occurred during the job --username <username> Set authenticati on username --verbose Print more information while working
Import control arguments: --append Imports data in append mode --as-avrodatafile Imports data to Avro data files --as-parquetfile Imports data to Parquet files --as-sequencefile Imports data to SequenceFiles --as-textfile Imports data as plain text (default) --autoreset-to-one-mapper Reset the number of mappers to one mapper if no split key available --boundary-query <statement> Set boundary query for retrieving max and min value of the primary key --columns <col,col,col...> Columns to import from table --compression-codec <codec> Compression codec to use for import --delete-target-dir Imports data in delete mode --direct Use direct import fast path --direct-split-size <n> Split the input stream every 'n' bytes when importing in direct mode -e,--query <statement> Import results of SQL 'statement' --fetch-size <n> Set number 'n' of rows to fetch from the database when more rows are needed --inline-lob-limit <n> Set the maximum size for an inline LOB -m,--num-mappers <n> Use 'n' map tasks to import in parallel --mapreduce-job-name <name> Set name for generated mapreduce job --merge-key <column> Key column to use to join results --split-by <column-name> Column of the table used to split work units --split-limit <size> Upper Limit of rows per split for split columns of Date/Time/Timestamp and integer types. For date or timestamp fields it is calculated in seconds. split-limit should be greater than 0 --table <table-name> Table to read --target-dir <dir> HDFS plain table destination --validate Validate the copy using the configured validator --validation-failurehandler <validation-failurehandler> Fully qualified class name for ValidationFailureHandler --validation-threshold <validation-threshold> Fully qualified class name for ValidationThreshold --validator <validator> Fully qualified class name for the Validator --warehouse-dir <dir> HDFS parent for table destination --where <where clause> WHERE clause to use during import -z,--compress Enable compression
Incremental import arguments: --check-column <column> Source column to check for incremental change --incremental <import-type> Define an incremental import of type 'append' or 'lastmodified' --last-value <value> Last imported value in the incremental check column
Output line formatting arguments: --enclosed-by <char> Sets a required field enclosing character --escaped-by <char> Sets the escape character --fields-terminated-by <char> Sets the field separator character --lines-terminated-by <char> Sets the end-of-line character --mysql-delimiters Uses MySQL's default delimiter set: fields: , lines: \n escaped-by: \ optionally-enclosed-by: ' --optionally-enclosed-by <char> Sets a field enclosing character
Input parsing arguments: --input-enclosed-by <char> Sets a required field encloser --input-escaped-by <char> Sets the input escape character --input-fields-terminated-by <char> Sets the input field separator --input-lines-terminated-by <char> Sets the input end-of-line char --input-optionally-enclosed-by <char> Sets a field enclosing character
Hive arguments: --create-hive-table Fail if the target hive table exists --external-table-dir <hdfs path> Sets where the external table is in HDFS --hive-database <database-name> Sets the database name to use when importing to hive --hive-delims-replacement <arg> Replace Hive record \0x01 and row delimiters (\n\r) from imported string fields with user-defined string --hive-drop-import-delims Drop Hive record \0x01 and row delimiters (\n\r) from imported string fields --hive-home <dir> Override $HIVE_HOME --hive-import Import tables into Hive (Uses Hive's default delimiters if none are set.) --hive-overwrite Overwrite existing data in the Hive table --hive-partition-key <partition-key> Sets the partition key to use when importing to hive --hive-partition-value <partition-value> Sets the partition value to use when importing to hive --hive-table <table-name> Sets the table name to use when importing to hive --map-column-hive <arg> Override mapping for specific column to hive types.
HBase arguments: --column-family <family> Sets the target column family for the import --hbase-bulkload Enables HBase bulk loading --hbase-create-table If specified, create missing HBase tables --hbase-row-key <col> Specifies which input column to use as the row key --hbase-table <table> Import to <table> in HBase
HCatalog arguments: --hcatalog-database <arg> HCatalog database name --hcatalog-home <hdir> Override $HCAT_HOME --hcatalog-partition-keys <partition-key> Sets the partition keys to use when importing to hive --hcatalog-partition-values <partition-value> Sets the partition values to use when importing to hive --hcatalog-table <arg> HCatalog table name --hive-home <dir> Override $HIVE_HOME --hive-partition-key <partition-key> Sets the partition key to use when importing to hive --hive-partition-value <partition-value> Sets the partition value to use when importing to hive --map-column-hive <arg> Override mapping for specific column to hive types.
HCatalog import specific options: --create-hcatalog-table Create HCatalog before import --drop-and-create-hcatalog-table Drop and Create HCatalog before import --hcatalog-storage-stanza <arg> HCatalog storage stanza for table creation
Accumulo arguments: --accumulo-batch-size <size> Batch size in bytes --accumulo-column-family <family> Sets the target column family for the import --accumulo-create-table If specified, create missing Accumulo tables --accumulo-instance <instance> Accumulo instance name. --accumulo-max-latency <latency> Max write latency in milliseconds --accumulo-password <password> Accumulo password. --accumulo-row-key <col> Specifies which input column to use as the row key --accumulo-table <table> Import to <table> in Accumulo --accumulo-user <user> Accumulo user name. --accumulo-visibility <vis> Visibility token to be applied to all rows imported --accumulo-zookeepers <zookeepers> Comma-separated list of zookeepers (host:port)
Code generation arguments: --bindir <dir> Output directory for compiled objects --class-name <name> Sets the generated class name. This overrides --package-name. When combined with --jar-file, sets the input class. --escape-mapping-column-names <boolean> Disable special characters escaping in column names --input-null-non-string <null-str> Input null non-string representation --input-null-string <null-str> Input null string representation --jar-file <file> Disable code generation; use specified jar --map-column-java <arg> Override mapping for specific columns to java types --null-non-string <null-str> Null non-string representation --null-string <null-str> Null string representation --outdir <dir> Output directory for generated code --package-name <name> Put auto-generated classes in this package
Generic Hadoop command-line arguments: (must preceed any tool-specific arguments) Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is: command [genericOptions] [commandOptions]
At minimum, you must specify --connect and --table Arguments to mysqldump and other subprograms may be supplied after a '--' on the command line.
Import failed: java.io.IOException: Query [SELECT * FROM emp WHERE EMPNO>=7900] must contain '$CONDITIONS' in WHERE clause.` -e "SELECT * FROM emp WHERE EMPNO>=7900" 应该写成: -e "SELECT * FROM emp WHERE EMPNO>=7900 AND \$CONDITIONS"
[hadoop@hadoop001 ~]$ sqoop help export Warning: /home/hadoop/app/sqoop/../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /home/hadoop/app/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /home/hadoop/app/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /home/hadoop/app/sqoop/../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 2022-02-28 11:50:42,057 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop export [GENERIC-ARGS] [TOOL-ARGS]
Common arguments: --connect <jdbc-uri> Specify JDBC connect string --connection-manager <class-name> Specify connection manager class name --connection-param-file <properties-file> Specify connection parameters file --driver <class-name> Manually specify JDBC driver class to use --hadoop-home <hdir> Override $HADOOP_MAPRED_HOME_ARG --hadoop-mapred-home <dir> Override $HADOOP_MAPRED_HOME_ARG --help Print usage instructions --metadata-transaction-isolation-level <isolationlevel> Defines the transaction isolation level for metadata queries. For more details check java.sql.Connection javadoc or the JDBC specificaiton --oracle-escaping-disabled <boolean> Disable the escaping mechanism of the Oracle/OraOop connection managers Read password from console --password <password> Set authenticati on password --password-alias <password-alias> Credential provider password alias --password-file <password-file> Set authentication password file path --relaxed-isolation Use read-uncommitted isolation for imports --skip-dist-cache Skip copying jars to distributed cache --temporary-rootdir <rootdir> Defines the temporary root directory for the import --throw-on-error Rethrow a RuntimeException on error occurred during the job --username <username> Set authentication username --verbose Print more information while working Export control arguments: --batch Indicates underlying statements to be executed in batch mode --call <arg> Populate the table using this stored procedure (one call per row) --clear-staging-table Indicates that any data in staging table can be deleted --columns <col,col,col...> Columns to export to table --direct Use direct export fast path --export-dir <dir> HDFS source path for the export -m,--num-mappers <n> Use 'n' maptasks toexport in parallel --mapreduce-job-name <name> Set name for generated mapreduce job --staging-table <table-name> Intermediate staging table --table <table-name> Table to populate --update-key <key> Update records by specified key column --update-mode <mode> Specifies how updates are performed when new rows are found with non-matching keys in database --validate Validate the copy using the configured validator --validation-failurehandler <validation-failurehandler> Fully qualified class name for ValidationFailureHandler --validation-threshold <validation-threshold> Fully qualified class name for ValidationThreshold --validator <validator> Fullyqualified class name for the Validator
Input parsing arguments: --input-enclosed-by <char> Sets a required field encloser --input-escaped-by <char> Sets the input escape character --input-fields-terminated-by <char> Sets the input field separator --input-lines-terminated-by <char> Sets the input end-of-line char --input-optionally-enclosed-by <char> Sets a field enclosing character
Output line formatting arguments: --enclosed-by <char> Sets a required field enclosing character --escaped-by <char> Sets the escape character --fields-terminated-by <char> Sets the field separator character --lines-terminated-by <char> Sets the end-of-line character --mysql-delimiters Uses MySQL's default delimiter set: fields: , lines: \n escaped-by: \ optionally-enclosed-by: ' --optionally-enclosed-by <char> Sets a field enclosing character
Code generation arguments: --bindir <dir> Output directory for compiled objects --class-name <name> Sets the generated class name. This overrides --package-name. When combined with --jar-file, sets the input class. --escape-mapping-column-names <boolean> Disable special characters escaping in column names --input-null-non-string <null-str> Input null non-string representation --input-null-string <null-str> Input null string representation --jar-file <file> Disable code generation; use specified jar --map-column-java <arg> Override mapping for specific columns to java types --null-non-string <null-str> Null non-string representation --null-string <null-str> Null string representation --outdir <dir> Output directory for generated code --package-name <name> Put auto-generated classes in this package
HCatalog arguments: --hcatalog-database <arg> HCatalog database name --hcatalog-home <hdir> Override $HCAT_HOME --hcatalog-partition-keys <partition-key> Sets the partition keys to use when importing to hive --hcatalog-partition-values <partition-value> Sets the partition values to use when importing to hive --hcatalog-table <arg> HCatalog table name --hive-home <dir> Override $HIVE_HOME --hive-partition-key <partition-key> Sets the partition key to use when importing to hive --hive-partition-value <partition-value> Sets the partition value to use when importing to hive --map-column-hive <arg> Override mapping for specific column to hive types.
Generic Hadoop command-line arguments: (must preceed any tool-specific arguments) Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is: command [genericOptions] [commandOptions]
At minimum, you must specify --connect, --export-dir, and --table
[hadoop@hadoop001 ~]$ sqoop job --help Warning: /home/hadoop/app/sqoop/../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /home/hadoop/app/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /home/hadoop/app/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /home/hadoop/app/sqoop/../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 2022-03-01 15:55:19,426 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop job [GENERIC-ARGS] [JOB-ARGS] [-- [<tool-name>] [TOOL-ARGS]]
Job management arguments: --create <job-id> Create a new saved job --delete <job-id> Delete a saved job --exec <job-id> Run a saved job --help Print usage instructions --list List saved jobs --meta-connect <jdbc-uri> Specify JDBC connect string for the metastore --show <job-id> Show the parameters for a saved job --verbose Print more information while working
Generic Hadoop command-line arguments: (must preceed any tool-specific arguments) Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is: command [genericOptions] [commandOptions]
[hadoop@hadoop001 ~]$ sqoop help eval 2022-03-01 16:38:37,514 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 usage: sqoop eval [GENERIC-ARGS] [TOOL-ARGS]
Common arguments: --connect <jdbc-uri> Specify JDBC connect string --connection-manager <class-name> Specify connection manager class name --connection-param-file <properties-file> Specify connection parameters file --driver <class-name> Manually specify JDBC driver class to use --hadoop-home <hdir> Override $HADOOP_MAPRED_HOME_ARG --hadoop-mapred-home <dir> Override $HADOOP_MAPRED_HOME_ARG --help Print usage instructions --metadata-transaction-isolation-level <isolationlevel> Defines the transaction isolation level for metadata queries. For more details check java.sql.Connection javadoc or the JDBC specificaiton --oracle-escaping-disabled <boolean> Disable the escaping mechanism of the Oracle/OraOop connection managers -P Read password from console --password <password> Set authenticati on password --password-alias <password-alias> Credential provider password alias --password-file <password-file> Set authentication password file path --relaxed-isolation Use read-uncommitted isolation for imports --skip-dist-cache Skip copying jars to distributed cache --temporary-rootdir <rootdir> Defines the temporary root directory for the import --throw-on-error Rethrow a RuntimeExcep tion on error occurred during the job --username <username> Set authentication username --verbose Print more information while working
SQL evaluation arguments: -e,--query <statement> Execute 'statement' in SQL and exit
Generic Hadoop command-line arguments: (must preceed any tool-specific arguments) Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is: command [genericOptions] [commandOptions]
[hadoop@hadoop001 ~]$ sqoop eval --connect jdbc:mysql://hadoop001:3306/ruozedata --username root --password '123456' --query "SELECT * FROM emp where deptno=10" 2022-03-01 16:45:12,146 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 2022-03-01 16:45:12,256 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2022-03-01 16:45:12,426 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. Tue Mar 01 16:45:12 GMT 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. ---------------------------------------------------------------------------------------------- | empno | ename | job | mgr | hiredate | sal | comm | deptno | ---------------------------------------------------------------------------------------------- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00.0 | 2450.00 | (null) | 10 | | 7839 | KING | PRESIDENT | (null) | 1981-11-17 00:00:00.0 | 5000.00 | (null) | 10 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00.0 | 1300.00 | (null) | 10 | ---------------------------------------------------------------------------------------------- [hadoop@hadoop001 ~]$ sqoop eval --connect jdbc:mysql://hadoop001:3306/ruozedata --username root --password 'ruozedata001' --query "INSERT INTO emp VALUES(7934,'KKK','CLERK',7782,'1985-01-20 00:00:00.0',1400,200,10)" 2022-03-01 16:49:02,886 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 2022-03-01 16:49:03,001 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2022-03-01 16:49:03,169 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. Tue Mar 01 16:49:03 GMT 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. 2022-03-01 16:49:03,566 INFO tool.EvalSqlTool: 1 row(s) updated. [hadoop@hadoop001 ~]$ sqoop eval --connect jdbc:mysql://hadoop001:3306/ruozedata --username root --password 'ruozedata001' --query "SELECT * FROM emp where deptno=10" 2022-03-01 16:49:28,104 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 2022-03-01 16:49:28,239 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 2022-03-01 16:49:28,391 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. Tue Mar 01 16:49:28 GMT 2022 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or set useSSL=true and provide truststore for server certificate verification. ---------------------------------------------------------------------------------------------- | empno | ename | job | mgr | hiredate | sal | comm | deptno | ---------------------------------------------------------------------------------------------- | 7782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00.0 | 2450.00 | (null) | 10 | | 7839 | KING | PRESIDENT | (null) | 1981-11-17 00:00:00.0 | 5000.00 | (null) | 10 | | 7934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00.0 | 1300.00 | (null) | 10 | | 7934 | KKK | CLERK | 7782 | 1985-01-20 00:00:00.0 | 1400.00 | 200.00 | 10 | ----------------------------------------------------------------------------------------------