语句 insert ignore into INSERT IGNORE 与INSERT INTO的区别就是INSERT IGNORE会忽略数据库中已经存在 的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
insert into … on duplicate key update … 1 2 3 4 5 6 7 8 9 10 11 12 13 1.on duplicate key update 含义: 1)如果在INSERT语句末尾指定了 on duplicate key update,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE; 2)如果不会导致唯一值列重复的问题,则插入新行。 2. values(col_name)函数只是取当前插入语句中的插入值,并没有累加功能。 如:count = values(count) 取前面 insert into 中的 count 值,并更新 当有多条记录冲突,需要插入时,前面的更新值都被最后一条记录覆盖,所以呈现出取最后一条更新的现象。 如:count = count + values(count) 依然取前面 insert into 中的 count 值,并与原记录值相加后更新回数据库,这样,当多条记录冲突需要插入时,就实现了不断累加更新的现象。 注: 1.insert into ... on duplicate key update ... values() 这个语句 尽管在冲突时执行了更新,并没有插入,但是发现依然会占用 id 序号(自增), 2.如果要更新的字段是主键或者唯一索引,不能和表中已有的数据重复,否则插入更新都失败。
replace into 1 2 3 4 5 6 7 8 对表进行replace into操作的时候, 如果表只包含主键: 当不存在冲突时,replace into 相当于insert操作。 当存在冲突时,replace into 相当于update操作。 如果表包含主键和唯一性索引: 当不存在冲突时,replace into 相当于insert操作。 当存在主键冲突的时候是先delete 再insert,如果主键是自增的,则自增主键会做 +1 操作。 当存在唯一性索引冲突的时候是直接update。,如果主键是自增的,则自增主键会做 +1 操作。
REPLACE INTO table (unique_column,num) VALUES (‘$unique_value’,$num);
跟
INSERT INTO table (unique_column,num) VALUES(‘$unique_value’,$num) ON DUPLICATE UPDATE num=$num;还是有些区别的.
首先,因为新纪录与老记录的主键值不同,所以其他表中所有与本表老数据主键id建立的关联全部会被破坏。
其次,就是,频繁的REPLACE INTO 会造成新纪录的主键的值迅速增大。
看上面知道,其实insert into ... on duplicate key update ...也是会造成主键的值迅速增大的问题
1 2 3 4 5 请注意,没有出现在`REPLACE`语句中的列将使用默认值插入相应的列。 如果列具有`NOT NULL`属性并且没有默认值,并且您如果没有在`REPLACE`语句中指定该值,则MySQL将引发错误。这是`REPLACE`和`INSERT`语句之间的区别。 使用REPLACE语句时需要知道几个重点: 如果您开发的应用程序不仅支持MySQL数据库,而且还支持其他关系数据库管理系统(RDBMS),则应避免使用REPLACE语句,因为其他RDBMS可能不支持。代替的作法是在事务中使用DELETE和INSERT语句的组合。 如果在具有触发器的表中使用了REPLACE语句,并且发生了重复键错误的删除,则触发器将按以下顺序触发:在删除前删除,删除之后,删除后,如果REPLACE语句删除当前 行并插入新行。 如果REPLACE语句更新当前行,则触发BEFORE UPDATE和AFTER UPDATE触发器。
alter 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1) 加索引 mysql> alter table 表名 add index 索引名 (字段名1[,字段名2 …]); 2) 加主关键字的索引 mysql> alter table 表名 add primary key (字段名); 3) 加唯一限制条件的索引 mysql> alter table 表名 add unique 索引名 (字段名); 4) 删除某个索引 mysql> alter table 表名 drop index 索引名; 5) 增加字段 mysql> ALTER TABLE table_name ADD field_name field_type; 如果你需要指定新增字段的位置,可以使用MySQL提供的关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)。 6) 修改原字段名称及类型(modify或者change) mysql> ALTER TABLE table_name CHANGE old_field_name new_field_name field_type; 7) 删除字段 mysql> ALTER TABLE table_name DROP field_name;
WITH ROLLUP 在group分组字段的基础上再进行统计数据。搭配ifnull()或者COALESCE()使用对汇总值命名
添加外键约束 1 2 3 4 5 6 7 8 9 10 11 12 --sql语句创建表的同时添加外键约束 CREATE TABLE tb_UserAndRole --用户角色表 ( ID INT PRIMARY KEY IDENTITY(1,1), UserID INT NOT NULL,--用户ID RoleID INT NOT NULL,--角色ID foreign key(UserID) references tb_Users(ID)--tb_Users表的ID作为tb_UserAndRole表的外键 ) --2、添加外键约束(关联字段要用括号括起来) -- ALTER TABLE 从表 -- ADD CONSTRAINT 约束名 FOREIGN KEY (关联字段) references 主表(关联字段);
ALTER TABLE <数据表名> ADD CONSTRAINT <外键名>
函数 REPLACE(str,old_string,new_string) REPLACE()函数有三个参数,它将string中的old_string替换为new_string字符串。
REGEXP_REPLACE (expression, pattern, replace_string[, pos[, occurrence[, match_type]]]) REGEXP_REPLACE (expression, pattern, replace_string[, pos[, occurrence[, match_type]]])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 参数说明 REGEXP_REPLACE() 函数参数的解释是: expression:它是一个输入字符串,我们将通过正则表达式参数和函数对其进行搜索。 patterns:它表示子字符串的正则表达式模式。 replace_string:如果找到匹配项,将被替换的子字符串。 REGEXP_INSTR() 函数使用下面给出的各种可选参数: pos:它用于指定字符串中表达式中的位置以开始搜索。如果我们不指定此参数,它将从位置 1 开始。 occurrence:它用于指定我们要搜索的匹配项。如果我们不指定这个参数,所有出现的都会被替换。 match_type:它是一个字符串,可以让我们细化正则表达式。它使用以下可能的字符来执行匹配。 - c:它表示区分大小写的匹配。 - i:它表示不区分大小写的匹配。 - m:它代表 multiple-line 模式,允许在字符串中使用行终止符。默认情况下,此函数匹配字符串开头和结尾的行终止符。 - n:它用于修改 . (点)字符来匹配行终止符。 - u:它代表 Unix-only 行结尾。
案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 1、用’#‘替换字符串中的所有数字 SELECT regexp_replace('01234abcde56789','[0-9]','#') AS new_str FROM dual; 结果:#####abcde##### 用’#‘替换字符串中的数字0、9 SELECT regexp_replace(‘01234abcde56789’,’[09]’,’#’) AS new_str FROM dual; 结果:#1234abcde5678# 2、遇到非小写字母或者数字跳过,从匹配到的第4个值开始替换,替换为'' SELECT regexp_replace('abcdefg123456ABC','[a-z0-9]','',4) 结果:abcefg123456ABC SELECT regexp_replace('abcDEfg123456ABC','[a-z0-9]','',4) 结果:abcDEg123456ABC SELECT regexp_replace('abcDEfg123456ABC','[a-z0-9]','',7); 结果:abcDEfg13456ABC 遇到非小写字母或者数字跳过,将所有匹配到的值替换为'' SELECT regexp_replace('abcDefg123456ABC','[a-z0-9]','',0); 结果:DABC 3、格式化手机号,将+86 13811112222转换为(+86) 138-1111-2222,’+‘在正则表达式中有定义,需要转义。\\1表示引用的第一个组 SELECT regexp_replace('+86 13811112222','(\\+[0-9]{2})( )([0-9]{3})([0-9]{4})([0-9]{4})','(\\1)\\3-\\4-\\5',0); 结果:(+86)138-1111-2222 SELECT regexp_replace("123.456.7890","([[:digit:]]{3})\\.([[:digit:]]{3})\\.([[:digit:]]{4})","(\\1)\\2-\\3",0) ; SELECT regexp_replace("123.456.7890","([0-9]{3})\\.([0-9]{3})\\.([0-9]{4})","(\\1)\\2-\\3",0) ; 结果:(123)456-7890 4、将字符用空格分隔开,0表示替换掉所有的匹配子串。 SELECT regexp_replace('abcdefg123456ABC','(.)','\\1 ',0) AS new_str FROM dual; 结果:a b c d e f g 1 2 3 4 5 6 A B C SELECT regexp_replace('abcdefg123456ABC','(.)','\\1 ',2) AS new_str FROM dual; 结果:ab cdefg123456ABC 5、 SELECT regexp_replace("abcd","(.*)(.)$","\\1",0) ; 结果:abc SELECT regexp_replace("abcd","(.*)(.)$","\\2",0) ; 结果:d SELECT regexp_replace("abcd","(.*)(.)$","\\1-\\2",0) ; 结果:abc-d
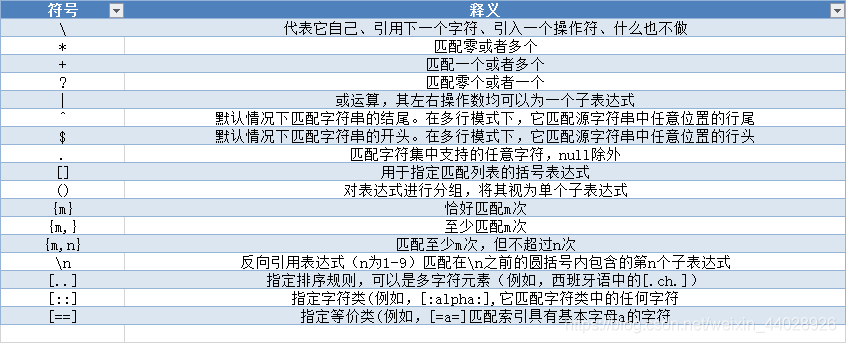
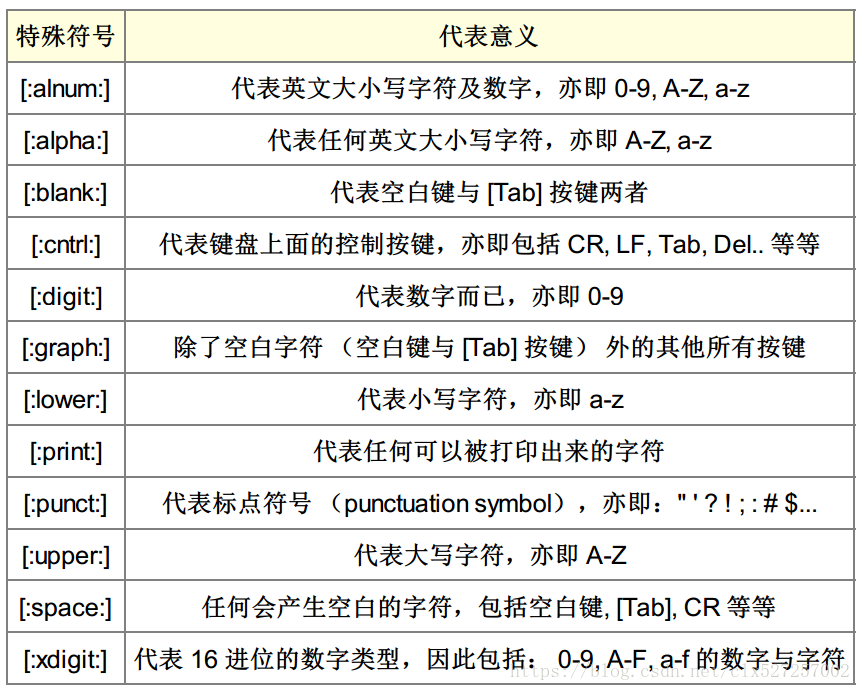
正则符号释义:
RIGHT(s,n)和LEFT(s,n) RIGHT(s,n) 函数返回字符串 s 最右边的 n 个字符。
LEFT(s,n) 函数返回字符串 s 最左边的 n 个字符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 mysql> SELECT RIGHT('MySQL',3); +------------------+ | RIGHT('MySQL',3) | +------------------+ | SQL | +------------------+ 1 row in set (0.00 sec) mysql> SELECT LEFT('MySQL',2); +-----------------+ | LEFT('MySQL',2) | +-----------------+ | My | +-----------------+ 1 row in set (0.04 sec)
group_concat(X,Y) 其中X是要连接的字段,Y是连接时用的符号,可省略,默认为逗号。此函数必须与 GROUP BY 配合使用。(=hive里的concat_ws(“,”,collect_set(字段)))
group_concat函数,实现分组查询之后的数据进行合并,并返回一个字符串结果。
格式:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
1 2 3 4 5 6 GROUP_CONCAT( DISTINCT expression ORDER BY expression SEPARATOR sep ); group_concat(distinct emp_no order by emp_no asc separator ',' )
last_day(curdate()); 获取当月最后一天
cast() 1 CAST (expression AS TYPE);
CAST()函数将任何类型的值转换为具有指定类型的值。目标类型可以是以下类型之一:BINARY,CHAR,DATE,DATETIME,TIME,DECIMAL,SIGNED,UNSIGNED。
CAST()函数通常用于返回具有指定类型的值,以便在WHERE、JOIN和HAVING子句中进行比较。
案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 在下面的例子中,在进行计算之前,MySQL将一个字符串隐式转换成一个整数: mysql> SELECT (1 + '1')/2; +-------------+ | (1 + '1')/2 | +-------------+ | 1 | +-------------+ 1 row in set SQL 要将字符串显式转换为整数,可以使用CAST()函数,如以下语句: mysql> SELECT (1 + CAST('1' AS UNSIGNED))/2; +-------------------------------+ | (1 + CAST('1' AS UNSIGNED))/2 | +-------------------------------+ | 1 | +-------------------------------+ 为了安全起见,可以使用CAST()函数将字符串显式转换为TIMESTAMP值 SELECT orderNumber, requiredDate FROM orders WHERE requiredDate BETWEEN CAST('2013-01-01' AS DATETIME) AND CAST('2013-01-31' AS DATETIME);//原文出
窗口函数LAG()和LEAD() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 LAG()函数是一个窗口函数,允许您回顾多行并从当前行访问行的数据。 LAG(<expression>[,offset[, default_value]]) OVER ( PARTITION BY expr,... ORDER BY expr [ASC|DESC],... ) expression:LAG()函数返回expression当前行之前的行的值,其值为offset 其分区或结果集中的行数。 offset:offset是从当前行返回的行数,以获取值。offset必须是零或文字正整数。如果offset为零,则LAG()函数计算expression当前行的值。如果未指定offset,则LAG()默认情况下函数使用一个。 default_value:如果没有前一行,则LAG()函数返回default_value。例如,如果offset为2,则第一行的返回值为default_value。如果省略default_value,则默认LAG()返回函数NULL。 PARTITION BY子句将结果集中的行划分LAG()为应用函数的分区。如果省略PARTITION BY子句,LAG()函数会将整个结果集视为单个分区。 ORDER BY 子句 ORDER BY子句指定在LAG()应用函数之前每个分区中的行的顺序。 LAG()函数可用于计算当前行和上一行之间的差异。 LEAD()函数是一个窗口函数,允许您向前看多行并从当前行访问行的数据。 与LAG()函数类似,LEAD()函数对于计算同一结果集中当前行和后续行之间的差异非常有用。
窗口函数指定窗口案例
1 2 3 4 5 sum(U_Id) over(partition by U_Pwd order by U_Id) 列1, sum(U_Id) over(partition by U_Pwd order by U_Id RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 列2, sum(U_Id) over(partition by U_Pwd order by U_Id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 列3, sum(U_Id) over(partition by U_Pwd order by U_Id ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING) 列4, sum(U_Id) over(partition by U_Pwd order by U_Id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) 列5
窗口函数NTH_VALUE() NTH_VALUE()函数返回expression窗口框架第N行的值。如果第N行不存在,则函数返回NULL。
MOD(N,M) 该函数返回N除以M后的余数. 分请看下面的例子:
1 2 3 4 5 6 7 mysql>SELECT MOD(29,3); +---------------------------------------------------------+ | MOD(29,3) | +---------------------------------------------------------+ | 2 | +---------------------------------------------------------+ 1 row in set (0.00 sec)
取整函数(ceil、floor、round) CEIL()函数:返回大于或等于数字的最小整数值。
floor()函数:返回小于或等于数字的最大整数值。
ROUND(X,D):此函数返回x舍入到最接近的整数。如果第二个参数,D有提供,则函数返回x四舍五入至第D位小数点。
SUBSTRING(string,position) SUBSTRING函数从特定位置开始的字符串返回一个给定长度的子字符串。 MySQL提供了各种形式的子串功能。
substring(被截取字段,从第几位开始截取)
1 2 3 4 5 6 mysql> SELECT SUBSTRING('MYSQL SUBSTRING', 7); +---------------------------------+ | SUBSTRING('MYSQL SUBSTRING', 7) | +---------------------------------+ | SUBSTRING | +---------------------------------+
注意,如果position参数为零,则SUBSTRING函数返回一个空字符串
1 2 3 4 5 6 7 mysql> SELECT SUBSTRING('MYSQL SUBSTRING', 0); +---------------------------------+ | SUBSTRING('MYSQL SUBSTRING', 0) | +---------------------------------+ | | +---------------------------------+ 1 row in set
substring_index(str,delim,count) substring_index(str,delim,count)
1 2 3 4 5 6 mysql> SELECT SUBSTRING_INDEX('blog.jb51.net', 2); +--------------------------------------------+ | SELECT SUBSTRING_INDEX('blog.jb51.net', 2) | +--------------------------------------------+ | blog.jb51 | +--------------------------------------------+
date_add()和date_sub() date_add():为日期增加一个时间间隔
date_sub():为日期减去一个时间间隔
1 2 3 4 5 6 7 8 9 10 select date_add(now(), interval 1 day); - 加1天 select date_add(now(), interval 1 hour); -加1小时 select date_add(now(), interval 1 minute); - 加1分钟 select date_add(now(), interval 1 second); -加1秒 select date_add(now(), interval 1 microsecond);-加1毫秒 select date_add(now(), interval 1 week);-加1周 select date_add(now(), interval 1 month);-加1月 select date_add(now(), interval 1 quarter);-加1季 select date_add(now(), interval 1 year);-加1年 MySQL date_sub() 日期时间函数 和date_add() 用法一致。
DATEDIFF() DATEDIFF() 函数返回两个日期之间的天数。前者减后者。
1 2 3 4 5 6 7 8 9 10 11 12 mysql> SELECT DATEDIFF('2008-12-30','2008-12-29') AS DiffDate +----------+ | DiffDate | +----------+ | 1 | +----------+ mysql> SELECT DATEDIFF('2008-12-29','2008-12-30') AS DiffDate +----------+ | DiffDate | +----------+ | -1 | +----------+
TIMESTAMPDIFF(unit,begin,end) TIMESTAMPDIFF函数返回begin-end的结果,其中begin和end是DATE 或DATETIME 表达式。
TIMESTAMPDIFF函数允许其参数具有混合类型,例如,begin是DATE值,end可以是DATETIME值。 如果使用DATE值,则TIMESTAMPDIFF函数将其视为时间部分为“00:00:00”的DATETIME值。
unit参数是确定(end-begin)的结果的单位,表示为整数。 以下是有效单位:
MICROSECOND、SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR
字段长度char_length和length char_length(str)
计算单位:字符
不管汉字还是数字或者是字母都算是一个字符
length(str)
计算单位:字节
utf8编码:一个汉字三个字节,一个数字或字母一个字节。
gbk编码:一个汉字两个字节,一个数字或字母一个字节。
MySQL5.0.3版本之后varchar类型大小的计算方式有所变化,从最早的按字节算大小varchar(length)改成了varchar(char_length)。
1)MySQL 5.0.3 之前:
数据类型大小:0–255字节
详解:varchar(20)中的20表示字节数,如果存放utf-8编码的话只能放6个汉字。varchar(n),这里的n表示字节数。
2)MySQL 5.0.3之后:
数据类型大小:0–65535字节,但最多占65532字节(其中需要用两个字节存放长度,小于255字节用1个字节存放长度)
详解:varchar(20)表示字符数,不管什么编码,不管是英文还是中文都可以存放20个。
COALESCE(value1,value2,…) COALESCE函数需要许多参数,并返回第一个非NULL参数。如果所有参数都为NULL,则COALESCE函数返回NULL。
REGEXP:正则表达式查询(rlike) 知识点
limit分页
select * from article LIMIT 3 OFFSET 1等价于select* from article LIMIT 1,3都表示取2,3,4三条条数据
select * from table limit (start-1)*pageSize,pageSize; 其中start 是页码,pageSize 是每页显示的条数。
页数公式:totalRecord是总记录数;pageSize是一页分多少条记录
1 int totalPageNum = (totalRecord +pageSize - 1) / pageSize;
MySQL分页查询优化
根据阿里巴巴Java开发规范v1.4中,数据库规约,关键词应大写,SELECT后面不要跟着“*”,要把具体的字段写出来。
group by vs distinct,group by性能高
对于distinct与group by的使用:
1、当对系统的性能高并数据量大时使用group by
2、当对系统的性能不高时使用数据量少时两者皆可
3、尽量使用group by
参考:MySQL中distinct和group by性能比较
触发器
1 2 3 4 5 6 create trigger audit_log after insert on employees_test for each row begin INSERT INTO audit (EMP_no,NAME) VALUES (new.id, new.name); end
报错:SQL_ERROR_INFO: “You can’t specify target table ‘titles_test’ for update in FROM clause”
原因:同一张表的 UPDATE 操作和 SELECT 不能同时进行
解决:在子查询中重命名表格名(必须),再进行 SELECT
update操作,要注意若干列之间只能用逗号连接,切勿用AND 连接。
mysql中修改表信息的规则。
alter table 表名 change 原列名 新列名 类型; –修改表的列属性名
alter table 表名 modify 列名 类型 ; –修改表的类类型
alter table 表名 drop 列名; –删除表的某一列
alter table 表名 add 列名 类型;–添加某一列
alter table 表名 rename 新表名; –修改表名
表改名
1 2 3 ALTER TABLE titles_test RENAME TO titles_2017; #另外一种写法: RENAME TABLE titles_test TO titles_2017;
SQL解决同一时刻最大数量问题
用union把in_time和out_time放到同一个表中,并添加一个字段diff区分,intime的值为1,outtime的值为-1,然后用窗口函数在每个时间点上做sum计算,有规定先算in再算out的话,order by再添加一个diff字段。