
一、Flume介绍与原理
Flume简介
Flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.9.4. 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Flume 在0.9.x and 1.x之间有较大的架构调整,1.x版本之后的改称Flume NG,0.9.x的称为Flume OG。
Flume目前只有Linux系统的启动脚本,没有Windows环境的启动脚本。
Flume是Apache的顶级项目,官方网站:http://flume.apache.org/
Flume NG的介绍
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
特点
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可靠性
event 在每个 agent 的 channel 中进行. 然后将 event 传递到流中的下一个 agent 或终端存储库(如 HDFS). 只有将 event 存储在下一个 agent 的 channel 或终端存储库中后, 才会从 channel 中删除这些 event . 这就是 Flume 中的单跳消息传递语义如何提供流的端到端可靠性.
Flume 使用事务方法来保证 event 的可靠传递. source 和 sink 分别在事务中封装由 channel 提供的事务中放置或提供的 event 的存储 / 检索. 这可确保 event 集在流中从一个点到另一个点可靠地传递. 在多跳流的情况下, 来自前一跳的 sink 和来自下一跳的 source 都运行其事务以确保数据安全地存储在下一跳的 channel 中.
(Flume支持在本地保存一份文件 channel 作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复。)
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:
- end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。)
- Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送)
- Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性
event 在 channel 中进行, 该 channel 管理从故障中恢复. Flume 支持由本地文件系统支持的持久文件 channel. 还有一个内存 channel, 它只是将 event 存储在内存中的队列中, 这更快, 但是当 agent 进程死亡时仍然留在内存 channel 中的任何 event 都无法恢复.
推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
Flume的一些核心概念
- Client:Client生产数据,运行在一个独立的线程。
- Event: Flume当中对数据的一种封装。是一个数据单元。flume传输数据最基本的单元,由消息头和消息体组成。(事务的基本单位,Events可以是日志记录、 avro 对象等。)
- Flow: Event从源点到达目的点的迁移的抽象。
- Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。)
- Source: 数据收集组件。(source从Client收集数据,传递给Channel)
- Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
- Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
- Channel Selector: 通道选择器,主要作用是根据用户配置将数据放到不同的Channel当中。
- Sink Processor:主要策略有,负载均衡,故障转移以及直通。
- Interceptor:拦截器,主要作用是将采集到的数据根据用户的配置进行过滤和修饰。
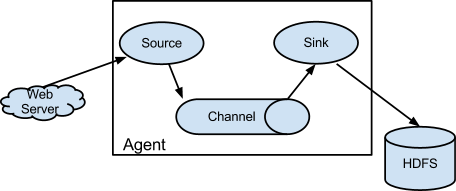
Flume NG的体系结构
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
Source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
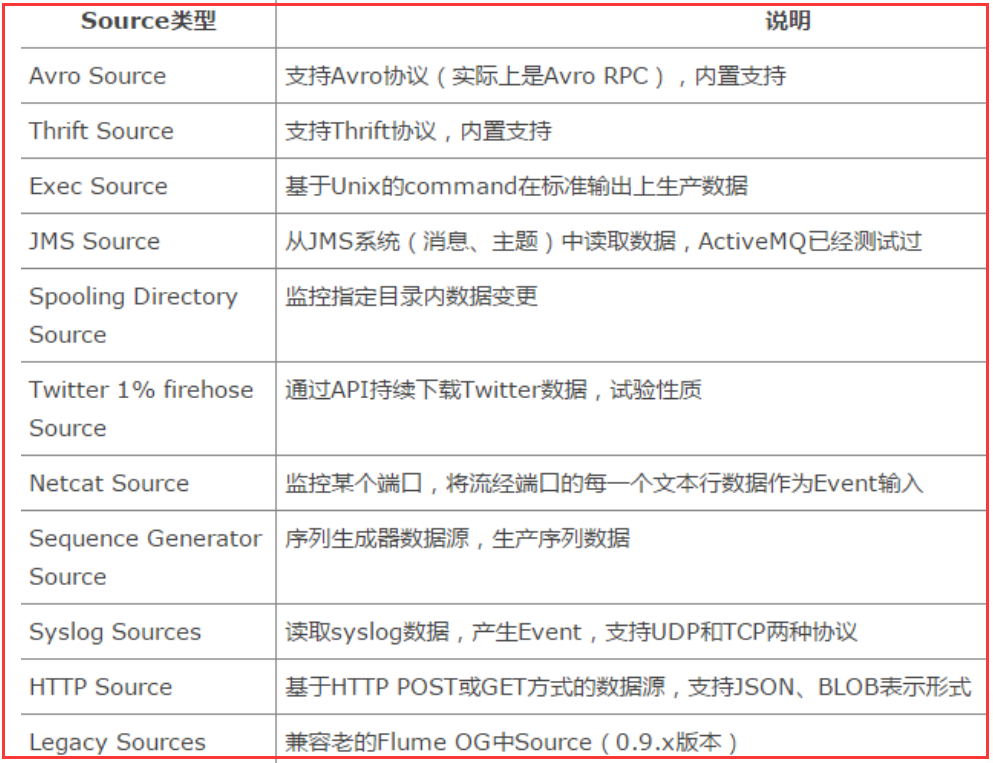
Source类型:
Channel
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。介绍两个较为常用的Channel, MemoryChannel和FileChannel。
- MemoryChannel可以实现高速的吞吐, 但是无法保证数据完整性
- FileChannel保证数据的完整性与一致性。在具体配置不现的FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
Channel类型:

Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
Sink类型:
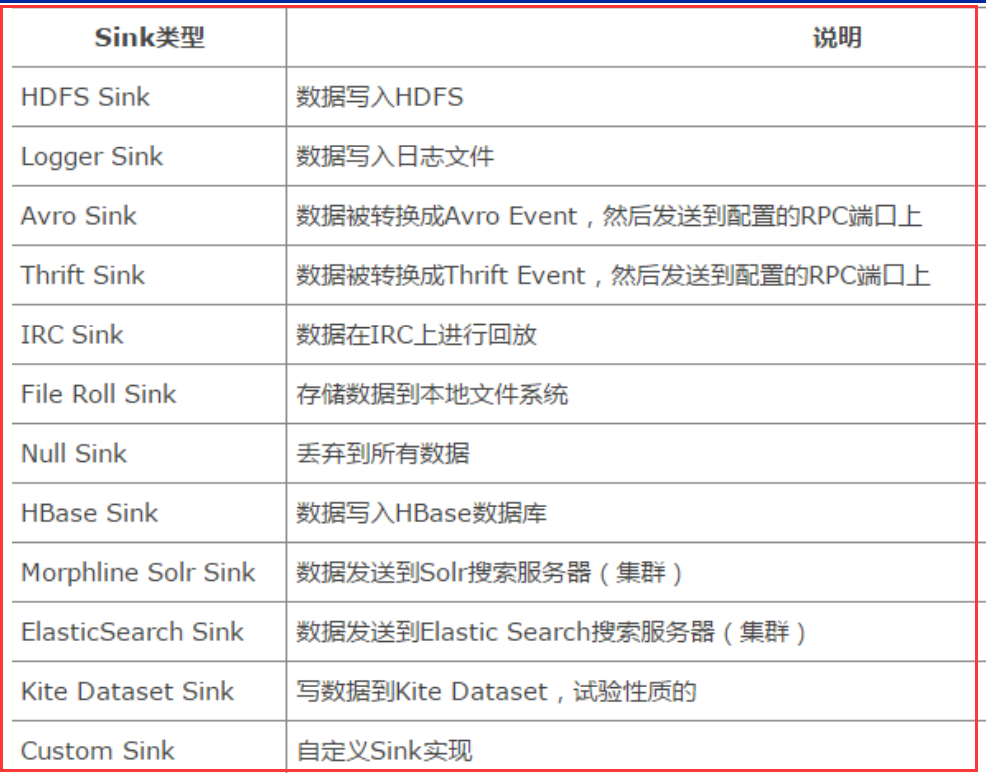
flume执行流程与事务
Flume 传输流程
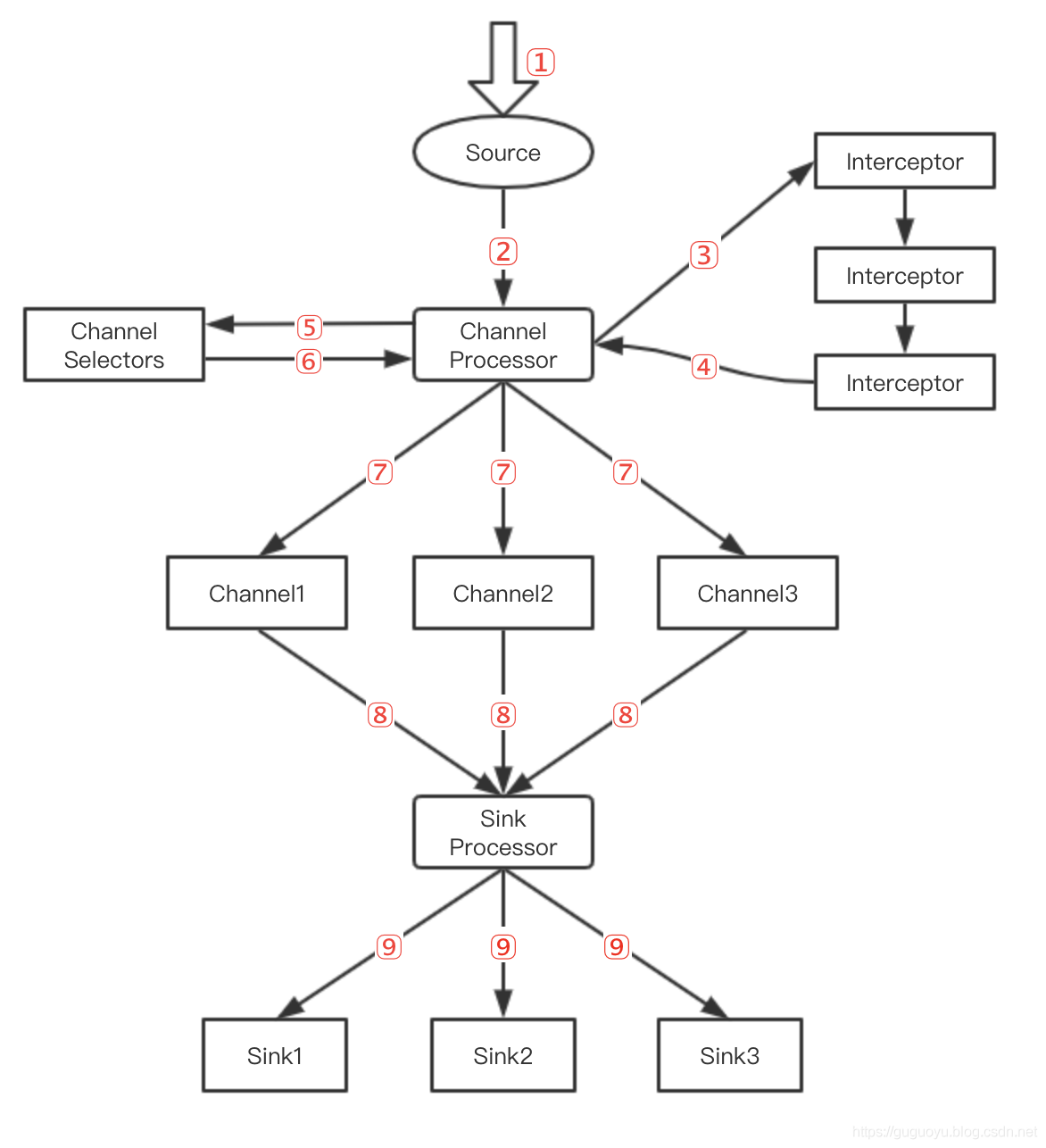
- Source 接受数据
- Channel Processor 处理 Event
- Channel Processor 将 Event 传递给 interceptor链对 Event 进行过滤操作
- 过滤完之后再把 Event 发送回 Channel Prodessor
- Channel Processor把 Event 发送给Channel selectors
- Channel selector返回Event 属于哪个Channel
- 根据第6步返回的结果,将Event发送到指定的Channel
- SinkProcessor从Channel中拉去数据
- 最后把数据Sink出去
重要组件:
Channel Selector
Channel Selector 的作用就是选出 Event 将要被发往哪个 Channel。共有两种类型,分别是 **Replicating Channel Selector (default)**(复制)和 Multiplexing Channel Selector(多路复用)。
Replicating Selector 会将 source 过来的每一个 Event 发往所有的 Channel,Multiplexing 会根据相应的原则,将不同的 Event 发往不同的 Channel。
Sink Processor
Sink Processor 共有三种类型,分别是 Default Sink Processor、Load Balancing Sink Processor 和 Failover Sink Processor。
Default Sink Processor 对应的是单个的 Sink,Load Balancing Sink Processor 和 Failover Sink Processor 对应的是 Sink Group。
Load Balancing Sink Processor 可以实现负载均衡的功能,Failover Sink Processor 可以实现故障转移的功能。
Flume 事务
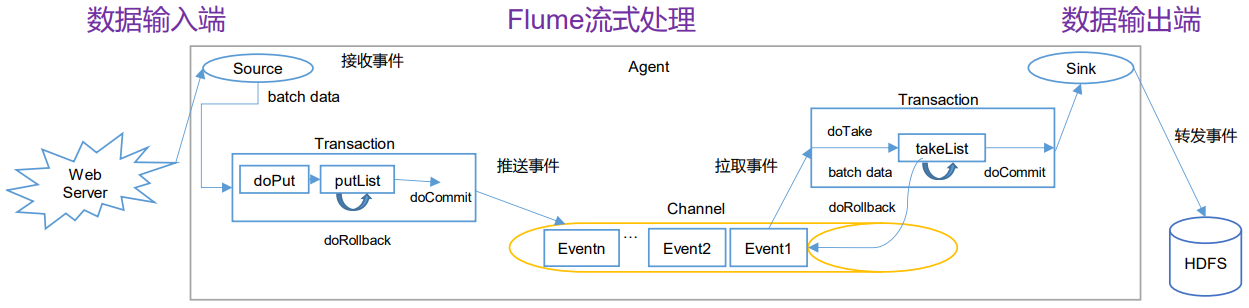
Put 事务流程
doPut:将批数据先写入临时缓冲区 putList
doCommit:检查 channel 内存队列是否足够合并
doRollback:channel 内存队列空间不足,回滚数据
Take 事务流程
doTake:将数据取到临时缓冲区 takeList,并将数据发送到 HDFS
doCommit:如果数据全部发送成功,则清除临时缓冲区 takeList
doRollback:数据发送过程中如果出现异常,rollback 将临时缓冲区 takeList 中的数据归还给 channel 内存队列
Flume的部署类型
单一流程
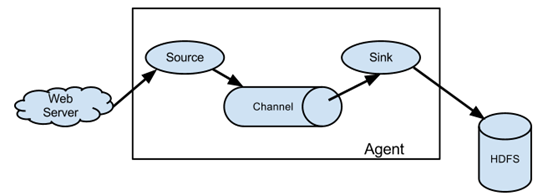
多代理流程(多个agent顺序连接)
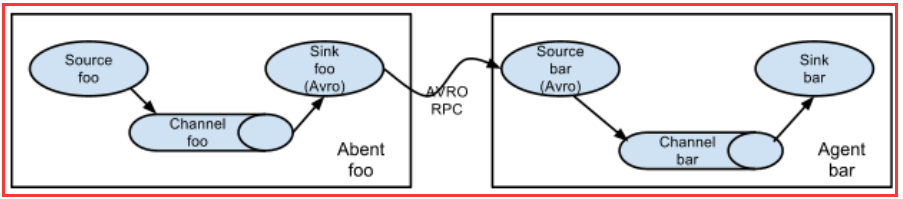
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
流的合并(多个Agent的数据汇聚到同一个Agent )
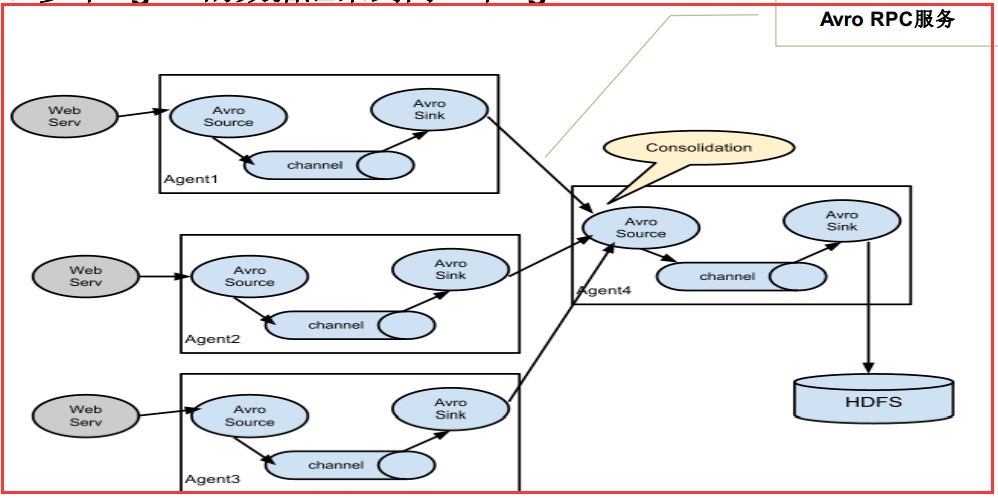
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为每 个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
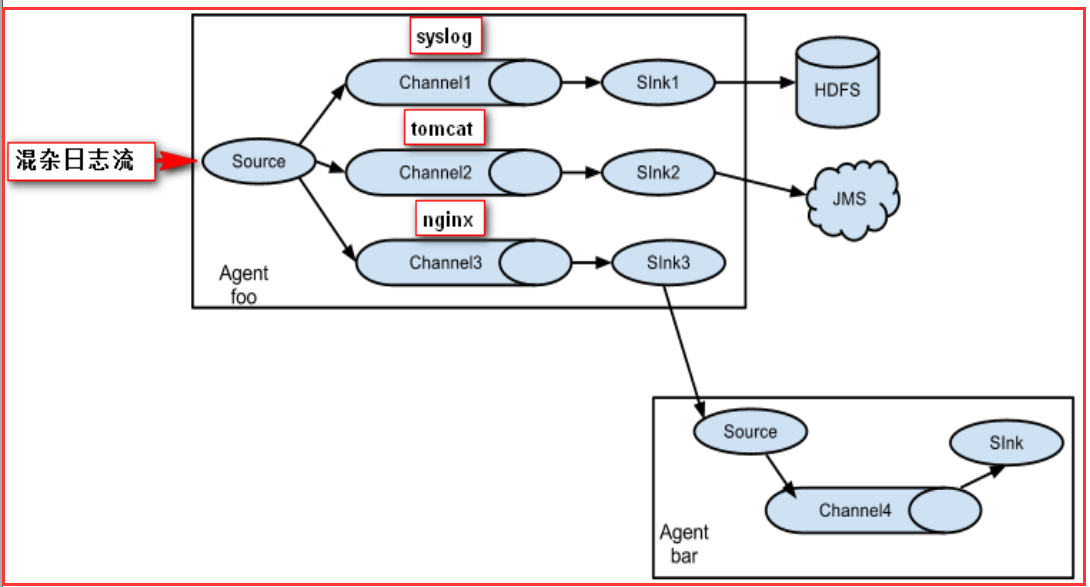
多路复用流(多级流)
Flume还支持多级流,什么多级流?来举个例子,当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent后,可以agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。
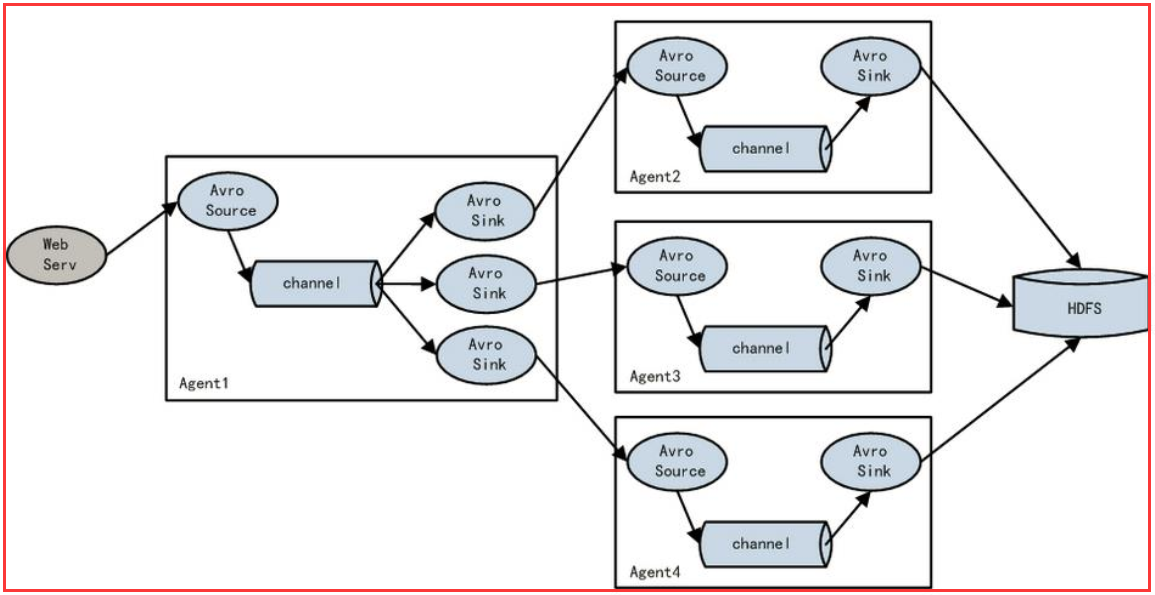
load balance功能
下图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上 。
个人笔记
Spooling Directory Source 如何使用?
Spooling Directory Source 监控文件夹中的日志信息。
在实际使用的过程中,可以结合log4j使用,使用log4j的时候,将log4j的文件分割机制设为1分钟一次,将文件拷贝到spool的监控目录。log4j有一个TimeRolling的插件,可以把log4j分割的文件到spool目录。基本实现了实时的监控。 Flume在传完文件之后,将会修改文件的后缀.tmp变为.COMPLETED(后缀也可以在配置文件中灵活指定)
但是有一定的问题,对于已经处理完的文件,后续再次处理或者重名则会报错。
flume中有几种可监控文件或目录的source
flume中有三种可监控文件或目录的source,分别是Exec Source、Spooling Directory Source和Taildir Source。
Taildir Source是1.7版本的新特性,综合了Spooling Directory Source和Exec Source的优点。
使用场景如下:
Exec Source
Exec Source可通过tail -f命令去tail住一个文件,然后实时同步日志到sink。但存在的问题是,当agent进程挂掉重启后,会有重复消费的问题。可以通过增加UUID来解决,或通过改进ExecSource来解决。
Spooling Directory Source
Spooling Directory Source可监听一个目录,同步目录中的新文件到sink,被同步完的文件可被立即删除或被打上标记。适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步。如果需要实时监听追加内容的文件,可对SpoolDirectorySource进行改进。
Taildir Source
Taildir Source可实时监控一批文件,并记录每个文件最新消费位置,agent进程重启后不会有重复消费的问题。
使用时建议用1.8.0版本的flume,1.8.0版本中解决了Taildir Source一个可能会丢数据的bug。
hdfs sink
会一直刷新文件。可以使用roll,设置hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount参数避免小文件问题。一个批次中,没有数据输入不产生文件。
Avro client
An Avro client included in the Flume distribution can send a given file to Flume Avro source using avro RPC mechanism:
1 | $ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10 |
The above command will send the contents of /usr/logs/log.10 to to the Flume source listening on that ports.
但是,Avro client 不适用于增量数据,对于增量数据,要采用avro sink到avro source的方式。
Flume如何保证数据传输的完整性?
事务机制
Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。比如以上面一篇博客中的事例为例:spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到channel且提交成功,那么source就将该文件标记为完成。同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚,且所有的事件都会保持到channel中,等待重新传递。
At-least-once提交方式
Flume的事务机制,总的来说,保证了source产生的每个事件都会传送到sink中。但是值得一说的是,实际上Flume作为高容量并行采集系统采用的是At-least-once(传统的企业系统采用的是exactly-once机制)提交方式,这样就造成每个source产生的事件至少到达sink一次,换句话说就是同一事件有可能重复到达。这样虽然看上去是一个缺陷,但是相比为了保证Flume能够可靠地将事件从source,channel传递到sink,这也是一个可以接受的权衡。
批处理机制
为了提高效率,Flume尽可能的以事务为单位来处理事件,而不是逐一基于事件进行处理。比如kafka source默认以消费100个event作为一个批次(BatchSize属性来配置,类似数据库的批处理模式)。批处理的设置尤其有利于提高file channle的效率,这样整个事务只需要写入一次本地磁盘,或者调用一次fsync,速度回快很多。
数据丢失问题?
根据Flume的架构原理,采用FileChannel的Flume是不可能丢失数据的,因为其内部有完善的事务机制(ACID)。
put 和 take 这两个事务是独立的,并且这两个环节都不可能丢失数据,唯一可能丢失数据的是 Channel 采用 MemoryChannel:
[1 ] 在 Agent 宕机时候导致数据在内存中丢失
[2 ] Channel 存储数据已满,导致 Source 不再写入数据,造成未写入的数据丢失
注:Flume不会丢失数据,但是可能会造成数据重复,例如数据已经由Sink发出,但是没有接收到响应,Sink会再次发送数据,导致数据重复。
Flume传输是否会丢失或重复数据?
这个问题需要分情况来看,需要结合具体使用的source、channel和sink来分析。
首先,分析source:
(1)exec source ,后面接 tail -f ,这个数据也是有可能丢的。
(2)TailDir source ,这个是不会丢数据的,它可以保证数据不丢失。
其次,分析sink:
(1)hdfs sink,数据有可能重复,但是不会丢失。一般生产过程中,都是使用 **TailDir source **和 HDFS sink,所以数据会重复但是不会丢失。
最后,分析channel:
要想数据不丢失的话,还是要用 File channel,而memory channel 在flume挂掉的时候还是有可能造成数据的丢失的。
二、Flume的安装与使用
Flume的安装
下载tar包
https://dlcdn.apache.org/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
将安装包上传到服务器并解压
1
2[hadoop@hadoop001 ~]$ cd software/
[hadoop@hadoop001 software]$ tar -xzvf apache-flume-1.9.0-bin.tar.gz创建软连接
1
[hadoop@hadoop001 software]$ $ ln -s /home/hadoop/software/apache-flume-1.9.0-bin /home/hadoop/app/flume
修改配置文件和环境变量
添加环境变量
1
[hadoop@hadoop001 ~]$ vi ~/.bash_profile
1
2
3export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin生效环境变量
1
[hadoop@hadoop001 ~]$ source ~/.bash_profile
修改配置文件:/home/hadoop/app/flume/conf
1
2
3
4
5
6
7
8
9[hadoop@hadoop001 ~]$ cd app/flume/conf/
[hadoop@hadoop001 conf]$ cp flume-env.sh.template flume-env.sh
[hadoop@hadoop001 conf]$ ll
total 20
-rw-r--r--. 1 hadoop hadoop 1661 Nov 16 2017 flume-conf.properties.template
-rw-r--r--. 1 hadoop hadoop 1455 Nov 16 2017 flume-env.ps1.template
-rw-r--r--. 1 hadoop hadoop 1568 May 16 21:21 flume-env.sh
-rw-r--r--. 1 hadoop hadoop 1568 Aug 30 2018 flume-env.sh.template
-rw-rw-r--. 1 hadoop hadoop 3107 Dec 10 2018 log4j.properties打开flume-env.sh文件,设置JAVA_HOME变量(根据已经安装的Java路径来设置)
1
2# export JAVA_HOME=/usr/lib/jvm/java-8-oracle
JAVA_HOME=/usr/java/jdk1.8.0_45检查版本
1
2
3
4
5
6[hadoop@hadoop001 ~]$ flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9如上信息证明安装成功。
注意:如果系统里安装了hbase,会出现错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty。如果没有安装hbase,这一步可以略过。
1
vi app/hbase/conf/hbase-env.sh
1
2
3
4
5#1、将hbase的hbase.env.sh的这一行配置注释掉,即在export前加一个#
#export HBASE_CLASSPATH=/home/hadoop/hbase/conf
#2、或者将HBASE_CLASSPATH改为JAVA_CLASSPATH,配置如下
export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#笔者用的是第一种方法
Flume的使用
设置
设置 agent
Flume agent 配置存储在本地配置文件中. 这是一个遵循 Java 属性文件格式的文本文件. 可以在同一配置文件中指定一个或多个 agent 的配置. 配置文件包括 agent 中每个 source,sink 和 channel 的属性以及它们如何连接在一起以形成数据流.
配置单个组件
流中的每个组件 (source,sink 或 channel) 都具有特定于类型和实例化的名称, 类型和属性集. 例如, Avrosource 需要主机名 (或 IP 地址) 和端口号来接收数据. 内存 channel 可以具有最大队列大小 (“容量”),HDFS sink 需要知道文件系统 URI, 创建文件的路径, 文件轮换频率(“hdfs.rollInterval”) 等. 组件的所有此类属性需要在托管 Flume agent 的属性文件中设置.
将各个部分连接在一起
agent 需要知道要加载哪些组件以及它们如何连接以构成流程. 这是通过列出 agent 中每个 source,sink 和 channel 的名称, 然后为每个 sink 和 source 指定连接 channel 来完成的. 例如, agent 通过名为 file-channel 的文件 channel 将 event 从名为 avroWeb 的 Avrosource 流向 HDFS sink hdfs-cluster1. 配置文件将包含这些组件的名称和文件 channel, 作为 avroWebsource 和 hdfs-cluster1 sink 的共享 channel.
启动 agent
使用名为 flume-ng 的 shell 脚本启动 agent 程序, 该脚本位于 Flume 发行版的 bin 目录中. 您需要在命令行上指定 agent 名称, config 目录和配置文件:
1 | $ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template |
现在, agent 将开始运行在给定属性文件中配置的 source 和 sink.
启动顺序,先启动sink(下游),再启动source(上游)。
案例一:netcat source
需求:监听localhost机器的44444端口,接收到数据sink到终端
创建agent配置文件
1
2[hadoop@hadoop001 ~]$ cd app/flume/conf/
[hadoop@hadoop001 conf]$ vi example.confexample.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# example.conf: A single-node Flume configuration
#需求:监听localhost机器的44444端口,接收到数据sink到终端
# Name the components on this agent 配置各种名字
a1.sources = r1 #配置source的名字
a1.sinks = k1 #配置sink的名字
a1.channels = c1 #配置channel的名字
# Describe/configure the source 配置source的基本属性
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Use a channel which buffers events in memory 配置channel的基本属性
a1.channels.c1.type = memory
# Describe the sink 配置sink的基本属性
a1.sinks.k1.type = logger
# Bind the source and sink to the channel 连线
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1This configuration defines a single agent named a1. a1 has a source that listens for data on port 44444, a channel that buffers event data in memory, and a sink that logs event data to the console. The configuration file names the various components, then describes their types and configuration parameters. A given configuration file might define several named agents; when a given Flume process is launched a flag is passed telling it which named agent to manifest.
启动flume agent a1
1
2
3
4
5flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console在另一个终端telnet localhost 44444 发送event
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[hadoop@hadoop001 ~]$ telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
1
OK
2
OK
3
OK
a
OK
b
OK
啊
OK第一个终端的日志控制台也会有相应的显示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[hadoop@hadoop001 conf]$ flume-ng agent \
> --name a1 \
> --conf $FLUME_HOME/conf \
> --conf-file $FLUME_HOME/conf/example.conf \
> -Dflume.root.logger=INFO,console
Info: Sourcing environment configuration script /home/hadoop/app/flume/conf/flume-env.sh
Info: Including Hadoop libraries found via (/home/hadoop/app/hadoop/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/home/hadoop/app/hive) for Hive access
.
.
.
2022-05-16 21:57:12,297 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
2022-05-16 21:58:30,762 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 31 0D 1. }
2022-05-16 21:58:36,151 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 32 0D 2. }
2022-05-16 21:58:38,455 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 33 0D 3. }
2022-05-16 21:58:39,071 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 61 0D a. }
2022-05-16 21:58:39,847 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 62 0D b. }
2022-05-16 22:02:54,721 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: E5 95 8A 0D .... }补充一点,flume只能传递英文和字符,不能用中文。
更多案例在Flume的使用案例
参考链接:
https://www.cnblogs.com/zhangyinhua/p/7803486.html#_label0